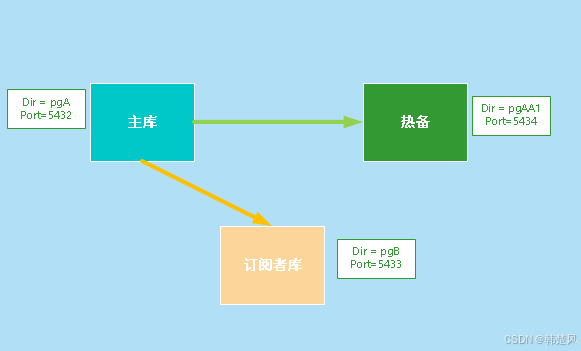
【PostgreSQL使用】最新功能逻辑复制槽的failover,大数据下高可用再添利器 使用数据库除了存取数据快捷以外,还有一个非常重要的目的,就是它有一整套的机制来保障数据访问的高可用,持续性。当然逻辑复制也不例外,当我们正在订阅的主库故障发生主备切换时,仍然希望数据库对象的变更订阅不... 国内服务器 2个月前250
构建大数据领域分布式存储的实战经验分享 电商平台每天产生PB级用户行为日志基因测序项目需要存储EB级生物信息数据实时推荐系统要求毫秒级数据读取响应本文聚焦“如何构建一个能处理PB级数据、支持高并发读写、故障时自动恢复的分布式存储系统”,覆盖... 国内服务器 2个月前250
【Hadoop+Spark+python毕设】气象地质灾害数据可视化分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 【Hadoop+Spark+python毕设】气象地质灾害数据可视化分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 国内服务器 2个月前260
WeArchive | 公众号文章保存工具 点击顶部导航栏的"设置"按钮可以配置以下选项:默认导出格式PDF页面大小和边距Word样式模板图片处理方式下载文件保存路径自动清理临时文件周期点击"保存设置"按... 国内服务器 2个月前510
大数据领域数据产品的安全保障策略 数据产品是以数据为核心生产要素,通过技术手段将数据转化为价值的产品分析型:BI工具(如Tableau)、用户画像系统;运营型:推荐引擎(如抖音推荐)、营销自动化平台;决策型:供应链预测系统、风险控制系... 国内服务器 2个月前280
大数据新视界 — Hive 集群搭建与配置的最佳实践(2 – 16 – 13) 本文围绕 Hive 集群搭建与配置,详述硬件选型、软件安装、配置优化、数据布局及高可用性等方面,含丰富案例与代码,具实用价值。 国内服务器 2个月前280
解决 RabbitMQ 的可靠性投递与消息重复消费问题思路 本文介绍了如何确保消息队列(MQ)在分布式系统中的可靠投递和防止重复消费。首先阐述了消息传递的四个关键阶段:生产者到交换机、交换机到队列、RabbitMQ存储、队列到消费者,并分别给出了Confirm... 国内服务器 2个月前280
Flutter 三方库 hive_ce_generator 无脑极速的 NoSQL 大数据对象存盘生成基石(适配鸿蒙 HarmonyOS Next ohos) 摘要:本文介绍了如何在OpenHarmony应用开发中使用hive_ce_generator工具实现高效数据持久化。该工具通过注解自动生成对象适配代码(TypeAdapter),简化了SQLite等数... 国内服务器 2个月前250
基于 Hadoop MapReduce + Spring Boot + Vue 3 的每日饮水数据分析平台 本文介绍了一个基于Hadoop MapReduce、Spring Boot和Vue 3的每日饮水数据分析平台。该平台采用前后端分离架构,实现了从数据采集、MapReduce分析处理到可视化展示的完整流... 国内服务器 2个月前290