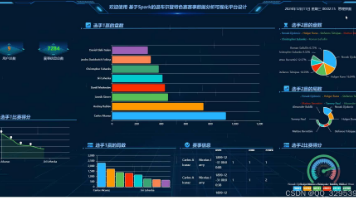
基于Spark的温布尔登特色赛赛事数据分析可视化平台设计与实现(源代码+文档+PPT+调试+讲解) 在网球赛事数据爆发式增长、温网特色赛(草地赛制、历史战绩、球员技战术)分析维度单一的背景下,基于 Spark 的温网赛事数据分析可视化平台,能解决 “海量数据处理效率低、技战术规律挖掘浅、分析结果不直... 国内服务器 2个月前300
基于深度学习的大数据时序预测模型构建指南 你是否遇到过这些场景?奶茶店老板需要预测明天的销量,避免原料浪费;电厂需要预测未来3天的用电负荷,调整发电计划;股民想根据历史股价预测下周走势……这些都属于时序预测(Time Series Forec... 国内服务器 2个月前270
Flink CDC 入门实战:从原理到踩坑全记录 (datastream/SQL 双版本) Flink CDC 实战:从原理到踩坑全记录 摘要:本文基于Flink 1.17和Flink CDC 2.4,详细介绍如何构建实时数据同步应用。Flink CDC凭借极简架构、全增量一体化读取和无锁算... 国内服务器 2个月前670
Spark持久化机制详解:从persist()到存储级别选择 对比维度核心优势极致性能稳定可靠适用数据量小于可用内存可大于可用内存容错能力依赖血统重算磁盘备份,无需重算GC压力较大较小适用场景小数据集、迭代算法大数据集、ETL作业选择口诀数据量小内存足,MEMO... 国内服务器 2个月前260
HiveSQL 语法详解与常用 SQL 写法实战 用于创建、修改和删除数据库和表。HiveSQL 凭借其类 SQL 的语法、强大的批处理能力和与 Hadoop 生态的深度集成,成为大数据离线分析的主流工具之一。掌握其核心语法和常用写法,不仅能高效完成... 国内服务器 2个月前300
Flink与Hive集成:批流一体的大数据仓库方案 传统批流分离的痛点与批流一体的价值Flink与Hive集成的核心技术原理(元数据、存储、计算层协同)从环境搭建到代码实战的全流程操作指南电商、金融等典型行业的落地场景本文将按照“故事引入→核心概念→原... 国内服务器 2个月前230
大数据分布式计算中的序列化优化 在分布式计算框架(如Apache Spark、Flink、Hadoop)中,数据需要在Worker节点、TaskExecutor、存储系统(如HDFS、Kafka)之间频繁传输。序列化性能直接影响系统... 国内服务器 2个月前230
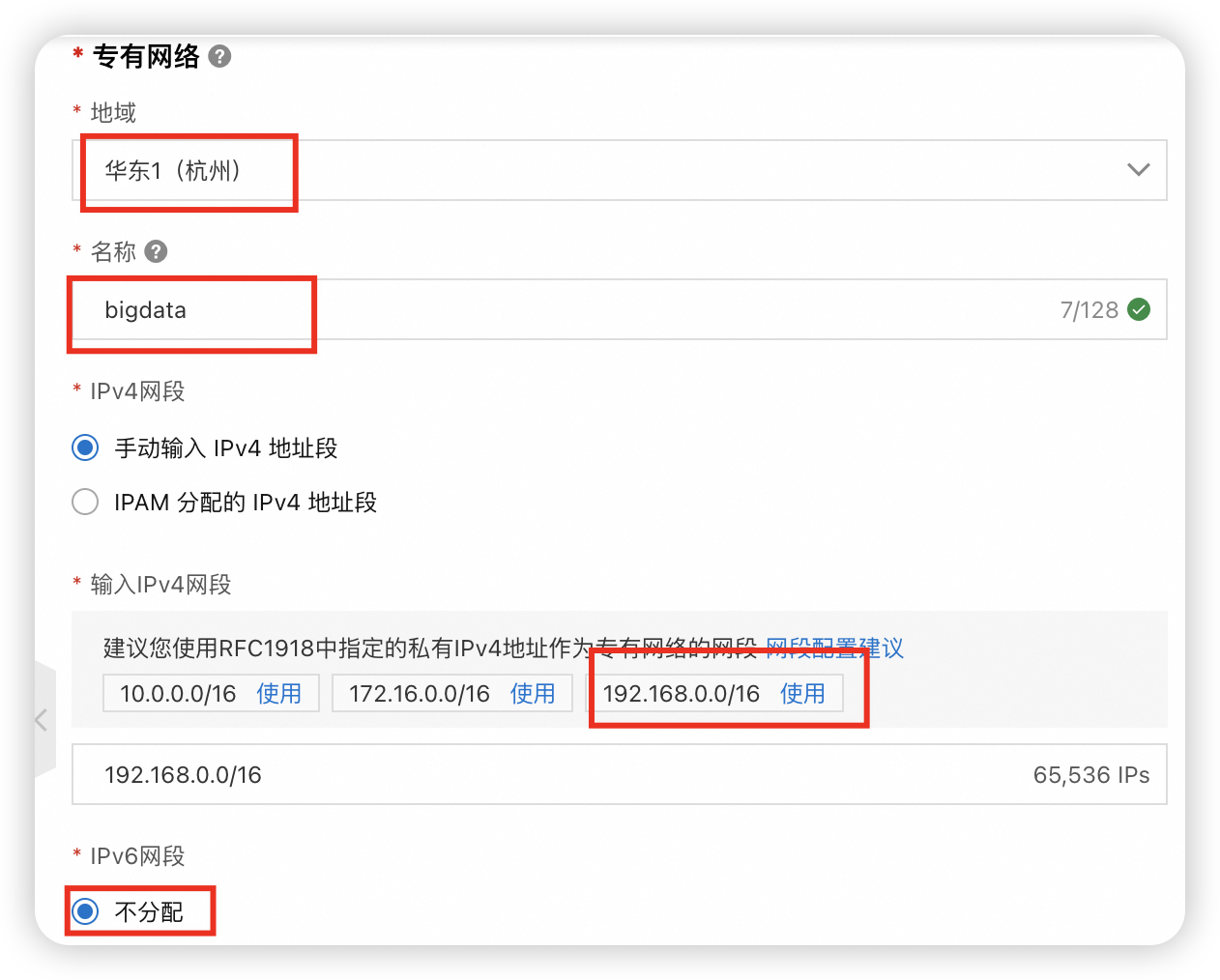
大数据各个服务配置合集【最新三节点高可用版本】 专有网络 VPC(Virtual Private Cloud)是云上安全隔离的虚拟网络环境,支持自定义网络配置、部署和访问云产品资源。VPC提供了类似于传统数据中心的安全和可配置的私有网络空间,同时又... 国内服务器 2个月前350
计算机毕业设计Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统 农产品销量预测 农产品推荐系统 智慧农业 本文介绍了一个基于Spark+Hadoop+Hive+LLM大模型+Django的农产品价格预测系统。系统通过整合多源数据(价格、天气、舆情等),采用五层分布式架构实现数据采集、存储、计算、预测与服务... 国内服务器 2个月前280