Kafka Consumer Group 详解:原理、机制与应用实践 在分布式消息系统中,如何高效地消费消息是一个核心问题。Apache Kafka 通过Consumer Group(消费者组)这一精妙的设计,完美解决了多个消费者协同消费、负载均衡、故障转移等问题。本文... 国内服务器 2个月前210
存储系统的容量规划与管理:从预测到优化 存储容量规划是指根据业务需求和数据增长趋势,预测存储系统的容量需求,并制定相应的扩容和管理策略的过程。满足需求:确保存储容量能够满足业务需求避免浪费:避免过度配置,减少资源浪费优化成本:优化存储成本... 国内服务器 2个月前270
大数据领域数据预处理的质量评估指标 数据预处理是大数据项目中最耗时且关键的环节,据统计,数据科学家80%的时间都花费在数据清洗和预处理上。本文旨在系统性地介绍数据预处理阶段的质量评估指标体系,帮助读者建立科学的数据质量评估框架。核心概念... 国内服务器 2个月前280
大数据处理中HBase的表设计最佳实践 高并发随机读写:如电商网站的用户购物车数据、社交平台的消息存储;海量数据存储:如物联网的传感器数据(每秒钟产生百万条记录);半结构化数据:如日志数据(字段不固定,需灵活扩展列)。HBase的表设计是技... 国内服务器 2个月前200
Internet Archive下载器完整教程:轻松获取数字图书馆珍贵资源 想要永久保存Internet Archive和HathiTrust数字图书馆中的珍贵书籍吗?Internet Archive下载器就是你的完美解决方案!这款强大的浏览器扩展能够轻松下载借阅书籍,让你随... 国内服务器 2个月前300
Spark RDD深度解析:The Definitive Guide低阶API使用手册 Apache Spark RDD(弹性分布式数据集)是Spark大数据处理框架的核心抽象,也是理解Spark分布式计算模型的基石。本文将基于Spark The Definitive Guide官方代码... 国内服务器 2个月前300
Kafka HW与LEO深度解析:副本同步核心指标 每个副本的最后一条消息的offset + 1,即下一条将要写入消息的offset。fill:#333;important;important;fill:none;color:#333;color:#3... 国内服务器 2个月前330
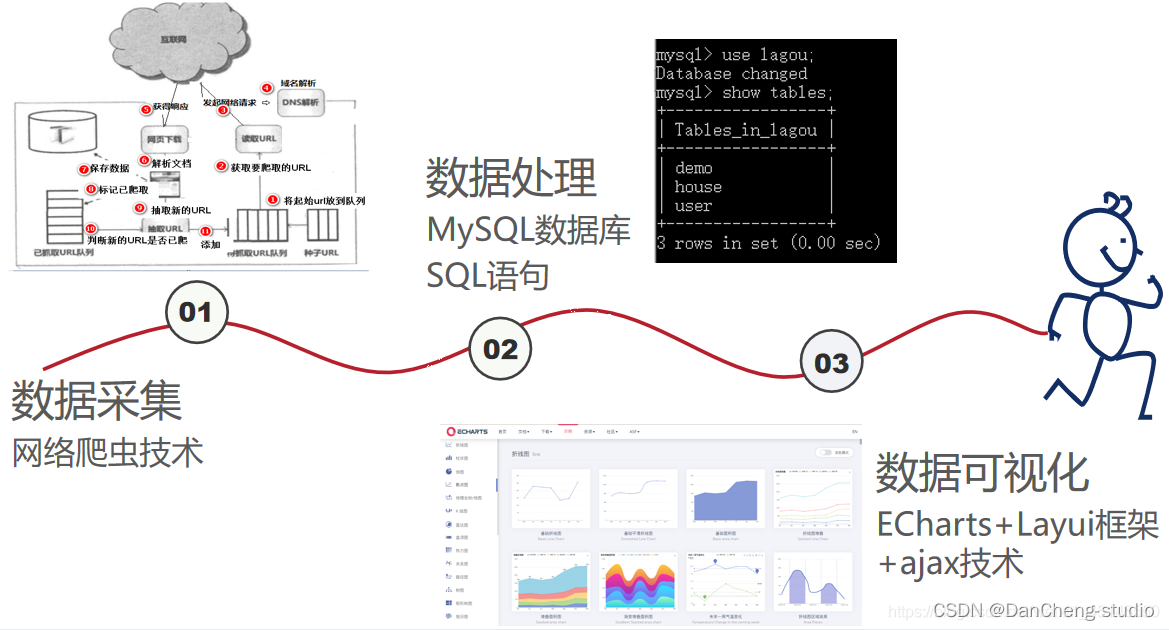
毕业设计 基于大数据的招聘与租房分析可视化系统 本文介绍了一个基于大数据的招聘与租房分析可视化系统。系统采用Python爬虫技术抓取拉勾网和链家等平台的招聘和租房数据,通过Ajax技术实现前后端交互,利用Echarts进行数据可视化展示。项目包含数... 国内服务器 2个月前290
Eureka 在大数据计算中的应用实践 Eureka 作为轻量级服务发现框架,完美适配大数据场景的「分布式、动态、高可用」需求。通过本文的实践,你已经掌握了 Eureka 在 Spark、Flink、Hadoop YARN 中的落地方法,以... 国内服务器 2个月前290