Eureka 在大数据计算中的应用实践 Eureka 作为轻量级服务发现框架,完美适配大数据场景的「分布式、动态、高可用」需求。通过本文的实践,你已经掌握了 Eureka 在 Spark、Flink、Hadoop YARN 中的落地方法,以... 国内服务器 2个月前290
《Windows Internals》10.1.20 Hive structure:为什么一个 Hive 在内部不是“键和值的平铺集合”,而是 block、base block、bin、cell 这种 本文解析了Windows注册表Hive的分层存储结构,指出其并非简单的键值平铺集合。Hive内部采用4KB block作为基础存储单元,首个base block存储全局元信息(如regf签名、校验和等... 国内服务器 2个月前310
Hadoop容错机制深度解析:从单点故障到集群自愈 fill:#333;important;important;fill:none;Hadoop容错体系数据容错副本机制数据块校验自动复制计算容错任务重试推测执行节点迁移服务容错ZooKeeper仲裁应用... 国内服务器 2个月前260
Dubbo- 注册中心实战:Zookeeper 部署与 Dubbo 集成配置 摘要:本文详细介绍了Dubbo与Zookeeper的集成实践,从注册中心的核心作用到Zookeeper单机/集群部署配置。主要内容包括: 注册中心原理:阐述Zookeeper如何通过临时节点、Watc... 国内服务器 2个月前330
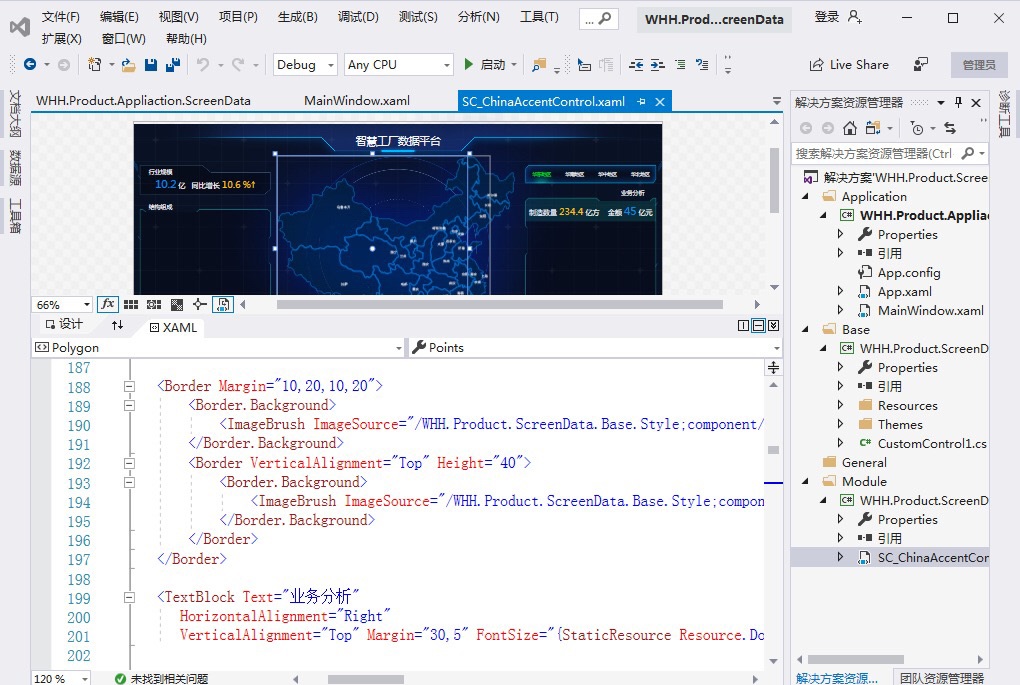
探索C# WPF大数据电子看板源码:打造智慧工厂数据平台 C#WPF大数据电子看板源码WPF智慧工厂数据平台1, 提供一个智慧工厂数据平台框架。2,理解wpf的设计模式。3,学习如何绘制各种统计图。4,设计页面板块划分。5,如何在适当时候展现动画。6,提供纯... 国内服务器 2个月前260
RabbitMQ 驱动下的工厂模式:AI 对话式向量化架构的“消息派单”实战 本文介绍了在campusai智慧园区项目中,如何通过工厂模式结合消息队列实现后台公告管理与AI向量化服务的解耦方案。针对后台管理系统版本低、业务类型多样化的挑战,设计了基于RabbitMQ的消息驱动架... 国内服务器 2个月前260
Stable-Diffusion-v1-5-archive企业合规实践:生成内容水印嵌入+版权元数据自动标注 本文介绍了如何在星图GPU平台上自动化部署stable-diffusion-v1-5-archive镜像,并为企业级应用构建合规解决方案。该方案通过在AI生成的图片中嵌入隐形水印和自动添加版权元数据... 国内服务器 2个月前300
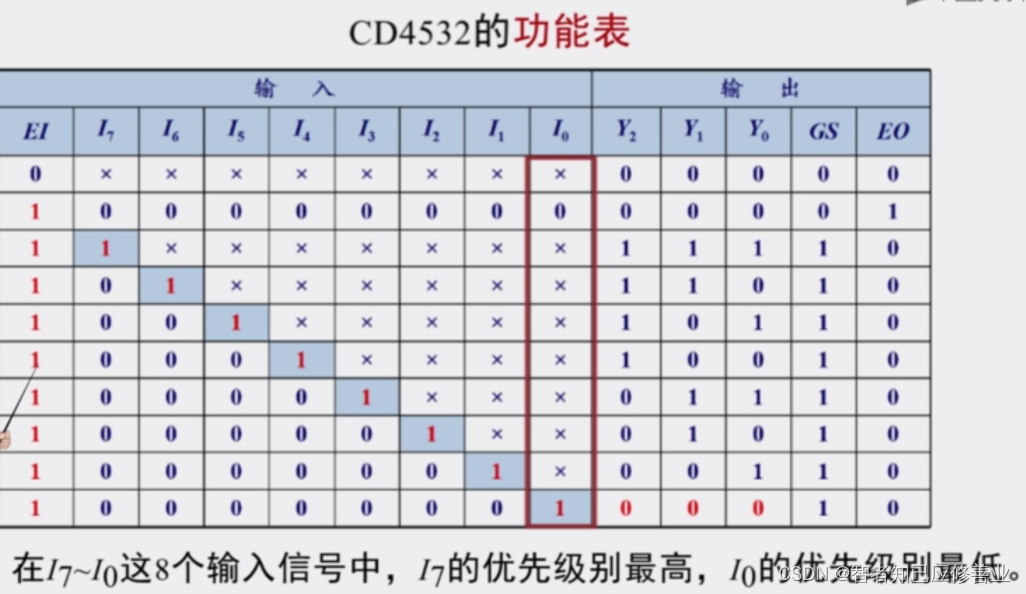
【CD4532/74HC147/74HC283组成的9线BCD编码器加减法器】2023-4-18 该内容讨论了基于74HC147、74HC283等芯片的电路设计应用。74HC147是10线-4线优先编码器,可将9个输入编码为BCD码输出;74HC283是4位二进制全加器。文中提到使用CD4532... 国内服务器 2个月前330
【51单片机实现0-7和8-1循环显示共阴数码管】2023-5-12 本文展示了基于51单片机的数码管驱动程序设计。程序实现了数码管自动循环显示功能,包含消隐处理、位值传送、段值传送和延时控制等核心驱动原则。通过位变量k控制显示方向切换,当正向显示时从8递减到1,反向显... 国内服务器 2个月前280