2026 高职大数据与会计专业证书报考门槛低含金量高的有哪些? 比如,同样是看一张利润表,普通会计看到的是数字对不对,而具备数据分析思维的财务人员会进一步追问:这个月的毛利为什么下降了?在备考的同时,多关注行业动态、多积累实践经验,把学到的知识真正转化为解决问题的... 国内服务器# 联通 3个月前280
大数据领域分布式存储的扩展性设计思路 在数据量以每年40%速度增长的当下,传统集中式存储架构面临容量上限(单节点磁盘容量通常<100PB)、IO瓶颈(单节点吞吐量<100万IOPS)、扩展性差(纵向扩展成本指数级增长)等核心问题。分布式存... 国内服务器 3个月前210
SPARKX i7:一台能够走进家庭的智能3D打印机 而如今,堵头则成为了最大的麻烦,一旦发生,很可能还需要拆机处理。但不同于以往的是,我们并不打算照搬过去的评测模式,而是希望用更通俗的语言,说清楚这台机器到底好在哪,它能在普通家庭里真正派上什么用场。而... 国内服务器 3个月前280
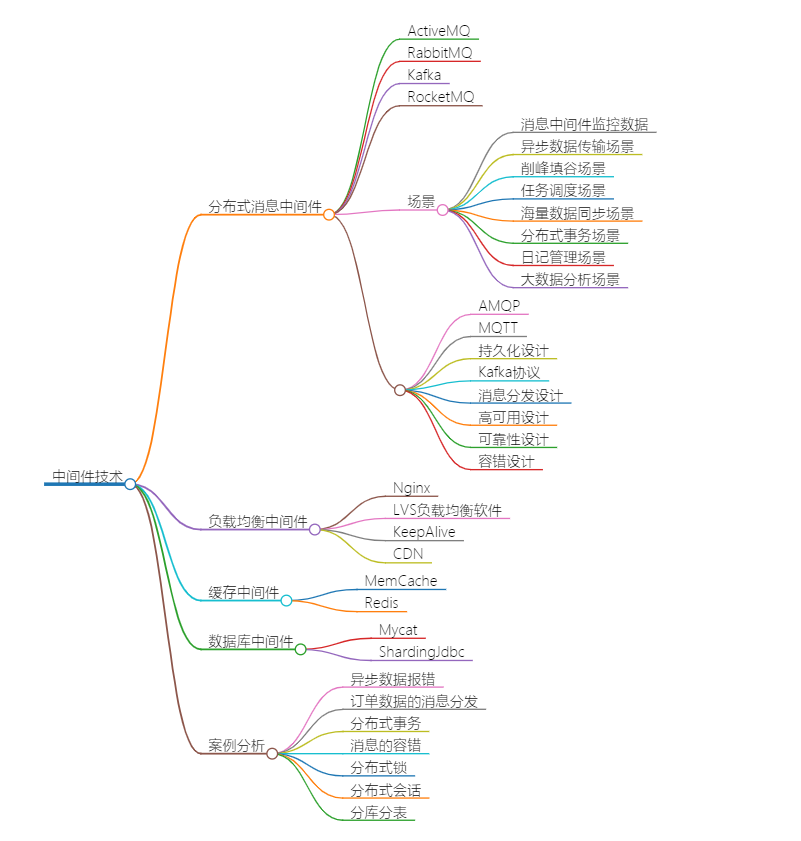
RabbitMQ 消息代理:从入门到精通 本文摘要: RabbitMQ是一种消息中间件,用于解决分布式系统中异构系统间的协同工作问题。它位于操作系统和应用之间,屏蔽底层复杂性,提供统一开发环境。RabbitMQ具有四大核心概念:生产者、交换机... 国内服务器 3个月前260
VxWorks版本的MSDN(1):任务管理API开发手册 摘要:本手册详细介绍了VxWorks实时操作系统的任务管理API,包含31个核心函数,涵盖任务创建、控制、查询和删除等全生命周期管理功能。VxWorks采用基于优先级的抢占式调度机制,支持256个优先... 国内服务器 3个月前310
Kafka Streams 实时流处理:构建高效数据管道 状态管理:合理使用状态存储窗口操作:选择合适的窗口类型性能优化:调整缓存和提交间隔监控运维:关注延迟和吞吐量这其实可以更优雅一点。流处理的设计要考虑数据的时效性和一致性。 国内服务器 3个月前250
大数据与元宇宙:虚拟世界数据分析 元宇宙作为下一代互联网形态,正在重塑人类的数字生活体验。在这个虚拟与现实交融的世界中,海量数据不断产生并流动。系统分析元宇宙环境中的数据特征和类型探讨大数据技术在虚拟世界中的创新应用提供可落地的数据分... 国内服务器 3个月前230
数据科学在大数据领域的安全保障 在当今数字化时代,大数据已经渗透到各个行业,如金融、医疗、零售等。大数据的应用为企业和社会带来了巨大的价值,但同时也引发了严重的数据安全问题。数据泄露、恶意攻击、数据篡改等事件频繁发生,给企业和个人带... 国内服务器 3个月前250
2025 RabbitMQ 面试题大全(精选90题) *虚拟主机(vHost)**是RabbitMQ中的逻辑隔离单元,用于在单个RabbitMQ实例上创建多个独立环境。多租户隔离:为不同团队或项目分配独立vHost。权限管理:通过vHost级别权限控制用... 国内服务器 3个月前200
计算机毕业设计hadoop+spark+hive薪资预测 招聘推荐系统 招聘可视化大屏 大数据毕业设计(源码+文档+PPT+ 讲解) 摘要:本研究基于Hadoop+Spark+Hive技术栈,开发薪资预测与招聘推荐系统,旨在解决传统招聘平台数据利用率低、匹配度差的问题。系统采用分层架构,整合多源数据,通过XGBoost+BERT集成... 国内服务器 3个月前270