Docker 部署分布式 Hadoop(超详细实战版) 本文详细介绍了使用Docker快速部署Hadoop分布式集群的完整流程。主要内容包括: 环境准备:在CentOS 7系统上安装配置Docker,创建基础镜像并安装必要工具 集群部署:基于基础镜像创建1... 国内服务器 3个月前350
解读大数据领域结构化数据的管理模式 随着企业数字化转型的深入,结构化数据作为最具业务价值的信息载体,其管理效率直接影响数据分析的准确性和决策支持的有效性。本文聚焦大数据领域结构化数据的管理模式,覆盖从数据采集、清洗、建模、存储到分析应用... 国内服务器 3个月前350
大数据毕设最新题目建议 毕业设计选题指南与方向推荐 本文为计算机相关专业学生提供毕业设计选题的系统性指导。首先阐述了选题的核心原则:能力匹配、兴趣驱动、就业导向、资源评估和创新实用。随后分享了9个实用选题技巧,包括逆向思维法... 国内服务器 3个月前350
Spark Datafusion Comet 向量化Rust Native–Native算子ScanExec以及涉及到的Selection Vectors Apache DataFusion Comet是苹果开源的Spark向量化加速项目,采用Spark插件化架构结合Protobuf、Arrow和DataFusion技术。其中,Selection Vec... 国内服务器 3个月前350
大数据领域核心 SQL 优化框架Apache Calcite介绍 Apache Calcite是一个开源的动态数据管理框架,专注于SQL解析、关系代数转换和查询优化。作为大数据领域SQL处理的"编译器内核",它被Flink、Hiv... 国内服务器 3个月前350
Ubuntu20.04搭建Hadoop大数据生态——从零开始:Ubuntu 20.04 搭建Hadoop+Hive+HBase+Spark大数据平台全攻略 本教程详细介绍了在Ubuntu 20.04系统上搭建Apache Hadoop大数据生态平台的完整流程。内容包括HDFS、YARN、Hive、HBase和Spark的安装配置,重点讲解了版本兼容性选择... 国内服务器 3个月前350
Kafka-King:三步搞定Kafka集群管理的终极指南 还在为复杂的Kafka命令行操作而头疼吗?Kafka-King作为一款现代化的Kafka图形化管理工具,让您告别繁琐配置,享受一键式操作带来的极致便捷。无论您是Kafka新手还是资深开发者,这款工具都... 国内服务器 3个月前350
Spark RDD五大核心特性 一个分区的、不可变的、有血缘记录的、惰性计算的分布式数据集合”。SparkRDD (Resilient Distributed Dataset,弹性分布式数据集)是 Spark 中最基本的数据抽象。它... 国内服务器 3个月前350
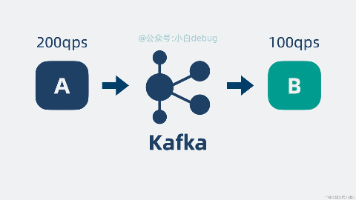
【Kafka进阶篇】拆解Kafka核心:LEO、HW与Leader Epoch的关联与应用 摘要: Kafka早期仅依赖高水位线(HW)定义消息可见性,但存在数据丢失和不一致的风险,尤其在故障切换后原Leader重新加入时,HW无法识别有效消息导致盲目截断。为此,Kafka 0.11引入Le... 国内服务器 3个月前350