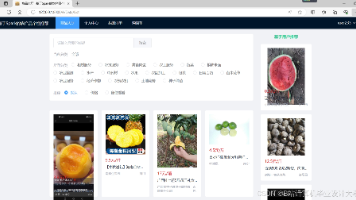
计算机毕业设计Hadoop+PySpark+Scrapy爬虫农产品推荐系统 农产品爬虫 农产品可视化 农产品大数据 大数据毕业设计(代码+LW文档+PPT+讲解视频) 摘要:本文针对农产品电商供需匹配效率低、冷链损耗高等痛点,提出基于Hadoop+PySpark+Scrapy的混合推荐系统。通过整合8类数据源构建24维特征矩阵,采用协同过滤、内容推荐和时序预测的三阶... 国内服务器 3个月前240
Kafka Streams聚合性能优化:3大瓶颈与4种提升策略 掌握Kafka Streams聚合操作性能优化关键,解决吞吐量低、延迟高、资源占用多三大瓶颈。涵盖窗口聚合、状态存储优化与并行处理等四大策略,适用于实时统计、指标监控等场景,显著提升处理效率,值得收藏... 国内服务器 3个月前220
PySpark Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代... 国内服务器 3个月前240
Kafka重平衡(Rebalance)深度解析:原理、影响与优化策略 本文深入探讨Kafka消费者组重平衡机制,分析其触发条件、影响及优化方案。重平衡会导致消费者暂停、消息重复消费和吞吐量下降,主要触发因素包括消费者增减、心跳超时等。优化策略包括:合理配置session... 国内服务器 3个月前270
Microi 吾码:大数据浪潮中的智能领航者 在大数据的浩瀚海洋中,Microi 吾码犹如一艘智能领航者,从数据存储、处理与分析、可视化、流式处理到安全与隐私保护以及云平台集成等多个方面,为大数据应用提供了全面而强大的支持。通过丰富的代码示例和深... 国内服务器 3个月前220
【即时通讯项目】环境搭建8——RabbitMQ,AMQP-CPP RabbitMQRabbitMQ 是一个消息中间件,你可以把它理解成一个专门负责接收、存储和转发消息的程序。它让不同的软件系统或者同一个系统的不同模块之间可以相互通信,但不需要直接连接对方。它的工作方... 国内服务器 3个月前290
django-flask基于大数据的电子商务个性化推荐系统 爬虫可视化分析 电子商务个性化推荐系统通过整合Django和Flask框架,结合大数据技术,实现了高效的商品推荐与用户行为分析。系统采用混合推荐算法(协同过滤与内容推荐),基于用户历史行为、商品属性及社交数据生成个性... 国内服务器 3个月前270
《数据治理实战指南》—【第三部分 实施篇】第7章 数据仓库及数据模型管理 数据仓库是为更好地分析和处理数据,面向主题来组织数据的存储系统。数据模型是定义数据结构、关系与规则的蓝图,是数据仓库的架构基础。数据模型决定了数据的组织逻辑与存储规范,数据仓库则是该模型的具体物理实现... 国内服务器 3个月前280
hive知识点 并行执行:默认情况下,Hive一次只会执行一个阶段,通过设置参数hive.exec.parallel值为true,就可以开启并发执行,将MapReduce阶段、抽样阶段、合并阶段、limit阶段,这些... 国内服务器 3个月前250