大数据场景时序数据库选型指南——Apache IoTDB实践与解析 本文探讨了大数据场景下时序数据库选型的关键维度,重点推荐了Apache IoTDB作为优选方案。文章从性能、生态兼容性、易用性、成本可控性和可扩展性五个核心维度分析了时序数据库选型标准。IoTDB凭借... 国内服务器 3个月前280
超详细指南:手把手教你构建Kafka Docker镜像 在当今云原生时代,掌握Kafka Docker镜像构建技能已成为开发者的必备能力。通过容器化部署Kafka,不仅能简化环境配置,还能提升系统的可移植性和扩展性。本文将为你揭秘完整的构建流程,让你轻松打... 国内服务器 2个月前250
Sarama:Go语言Kafka客户端完整指南 想象一下,当你需要在Go应用中集成Kafka消息队列时,面对复杂的协议细节和性能优化挑战,是否曾感到无从下手?Sarama正是为解决这一痛点而生,它为Go开发者提供了一个功能完整、性能卓越的Kafka... 国内服务器 3个月前320
大数据数据服务架构设计:核心要点与最佳实践 在当今数字化时代,大数据已经成为企业和组织的重要资产。大数据数据服务架构设计的目的在于构建一个高效、稳定、可扩展的架构,以支持对海量数据的存储、处理、分析和共享。本文章的范围涵盖了大数据数据服务架构设... 国内服务器 2个月前300
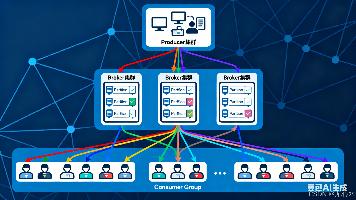
【分布式利器:Kafka】Kafka基本原理详解:架构、流转机制与高吞吐核心(附实战配置) Kafka是一个分布式流处理平台,以高吞吐、高可靠和高扩展性著称,广泛应用于日志收集、实时分析和数据同步场景。其核心架构包括生产者、消费者、Broker节点、Topic和Partition,通过分区并... 国内服务器 3个月前290
Apache Spark 入门到精通 想象你有一个非常大的Excel表格,有1亿行数据。用普通电脑打开?卡死!传统的单机处理方式(如Pandas)在面对“海量数据”时无能为力。是一个快速、通用的大数据处理引擎,它可以把任务分发到很多台机器... 国内服务器 2个月前310
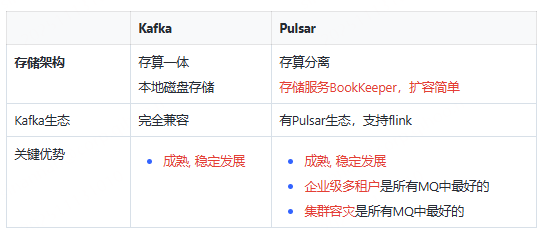
Kafka 消费积压影响写入?试试 Pulsar Pulsar 中 topic 消费积压不会导致写超时,Pulsar 读写磁盘分开,写数据使用WAL磁盘,顺序写,WAL的数据会在内存中赞批刷到Ledger磁盘,数据消费时,如果没命中缓存,从Ledge... 国内服务器 3个月前290
Java Web开发基础与Servlet核心技术 本文摘要: Java Web开发基础主要讲解Servlet核心技术及其应用。重点包括Web应用目录结构、Servlet定义与使用(通过继承HttpServlet类或实现Servlet接口)、HTTP请... 国内服务器 2个月前280
Sentinel – 使用 Apollo 或 ZooKeeper 存储规则:多注册中心适配 本文介绍了如何让Sentinel支持多种注册中心(如Apollo和ZooKeeper)来存储规则,提升微服务架构的灵活性。内容包括:1)多注册中心支持的必要性,满足不同技术栈需求;2)环境准备与Mav... 国内服务器 3个月前300