ZooKeeper ZNode的stat结构体深度解析:从字段详解到实战应用 stat结构体是ZooKeeper为每个ZNode维护的状态信息元数据,记录了节点的创建、修改、访问控制等所有关键操作的历史。可以把它理解为ZNode的"身份证"和"履历... 国内服务器 3个月前340
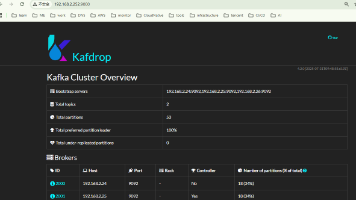
无zookeeper Kafka 4.1.0 Raft 集群搭建 实现高可用,集群若允许N个controller失败,则需要2N+1个controller组成集群。下面搭建一个3节点的Kafka集群,3个controller,3个broker。Kafka kraft... 国内服务器 3个月前340
Kubernetes–在k8s中安装和使用kafka Apache Kafka 作为当今最流行的分布式流处理平台之一,已被广泛应用于实时数据管道、事件驱动架构和流分析等场景。随着云原生技术的普及,在 Kubernetes 上运行 Kafka 已成为主流选... 国内服务器 3个月前340
基于神经网络的学生学习情况分析系统-hadoop+django 摘要:本研究开发了一个基于Python+Django框架的学生学习分析系统,采用B/S架构和MySQL数据库,通过LSTM算法实现成绩预测。系统包含用户管理、学习数据分析、成绩预测和可视化展示等功能模... 国内服务器 4个月前340
基于大数据爬虫+Hadoop+Python的农产品销售预测系统设计与实现开题报告 本文设计了一种基于大数据技术的农产品销售预测系统,旨在解决传统农产品销售中存在的产销失衡问题。系统整合大数据爬虫、Hadoop分布式计算和Python数据分析技术,构建从数据采集到预测输出的全流程解决... 国内服务器 4个月前340
ArchiveBox版本演进深度解析:从基础归档到企业级解决方案的5大关键跨越 ArchiveBox作为开源自托管网页归档工具,在版本迭代过程中实现了从简单网页抓取到完整企业级解决方案的重大转型。本文将从技术架构演进、功能升级路径、用户体验优化等维度,全面剖析ArchiveBox... 国内服务器 4个月前340
挖掘大数据领域交易数据中的潜在商机 随着企业数字化转型加速,日均产生的交易数据量呈指数级增长。据IDC预测,2025年全球数据总量将达175 ZB,其中交易数据占比超过30%。这些数据记录了用户购买行为、产品交互轨迹和市场动态,成为企业... 国内服务器 4个月前340
计算机毕业设计PySpark+Hive+大模型小红书评论情感分析 小红书笔记可视化 小红书舆情分析预测系统 大数据毕业设计(源码+LW+PPT+讲解) 摘要:本文提出基于PySpark、Hive与大模型的混合架构情感分析方案,针对小红书平台海量用户评论数据进行高效处理。系统采用分层架构设计,通过PySpark实现分布式计算,Hive构建高效数据仓库... 国内服务器 4个月前340
DGX Spark (Blackwell) 部署 Qwen3.6 35B FP8 踩坑实录:从无限崩溃到成功跑通 本文记录了在全新 NVIDIA DGX Spark G10(Blackwell ARM64架构)服务器上,使用 vLLM 部署 Qwen3.6-35B-A3B-FP8 模型的硬核踩坑实录。针对新硬件架... 国内服务器 2个月前330
Flink 安装部署 本文介绍了Apache Flink的安装部署指南,包括单机、分布式集群和YARN/Docker部署方式。主要内容涵盖:环境准备(JDK、Hadoop)、下载安装包、配置环境变量、Flink集群配置、启... 国内服务器 2个月前330