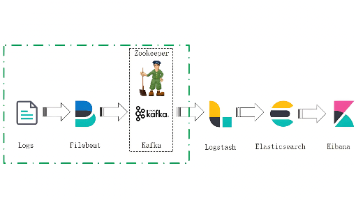
集成Kafka 、 ELK实现高吞吐日志采集是Filebeat 还是Fluentbit? 摘要:本文对比了两种高吞吐日志采集方案:Filebeat+Kafka+ELK和Fluentbit+Kafka+ELK。Filebeat专为结构化日志文件设计,配置简单、资源占用低;Fluentbit则... 国内服务器 2个月前330
【CCF主办 | 高认可度会议】第六届人工智能、大数据与算法国际学术会议(CAIBDA 2026) 所有的投稿都必须经过2-3位组委会专家审稿,经过严格的审稿之后,最终符合出版标准的稿件由IEEE出版,见刊后提交至EI Compendex, Scopus检索,往届会议皆已完成检索。◆ 投稿前可通过C... 国内服务器 2个月前330
支付扣款成功却未发货?Spring Boot 整合 Kafka 事务消息的物理级防丢防重生死局 本文探讨了Spring Boot与Kafka整合时可能遇到的支付扣款成功但未发货问题,分析了消息丢失和重复消费的底层物理原因,并提出了解决方案。文章首先描述了网络黑洞和消息重传导致的业务灾难场景,随后... 国内服务器 3个月前330
2025 Kafka 面试题大全(精选90题) 答案定义:由多个消费者实例组成的逻辑组,共享同一group.id,共同消费一个或多个Topic。设计目的负载均衡:将Topic分区分配给组内消费者,提高消费并行度。容错性:若消费者故障,其分区自动分配... 国内服务器 3个月前330
Kafka HW与LEO深度解析:副本同步核心指标 每个副本的最后一条消息的offset + 1,即下一条将要写入消息的offset。fill:#333;important;important;fill:none;color:#333;color:#3... 国内服务器 3个月前330
VxWorks版本的MSDN(1):任务管理API开发手册 摘要:本手册详细介绍了VxWorks实时操作系统的任务管理API,包含31个核心函数,涵盖任务创建、控制、查询和删除等全生命周期管理功能。VxWorks采用基于优先级的抢占式调度机制,支持256个优先... 国内服务器 3个月前330
用 Flink CDC 将 MySQL 实时同步到 Doris 本文演示如何在本地机器上通过 Flink CDC CLI 构建一个 Streaming ELT 作业,将 MySQL 的全量 + 增量数据同步到 Doris,并覆盖三个关键能力:整库同步、Schema... 国内服务器 3个月前330
MapReduce与Kafka实时数据处理 本文从“批处理的局限性”入手,介绍了Kafka的实时性优势,然后通过架构设计和实战,实现了Kafka+MapReduce的实时数据处理。核心要点回顾MapReduce:擅长大规模批处理,但延迟高;Ka... 国内服务器 3个月前330
【大数据存储与管理】分布式数据库HBase:02 HBase访问接口 本文讲解HBase的访问方式,各接口特点鲜明,适用场景不同,用户可依据如数据处理需求、系统环境等具体情况选择合适接口访问HBase。 国内服务器 3个月前330
AI时代:工程师的自我革命 如果有一天,你走进公司,发现写代码、查 bug、跑实验的大部分体力活,都已经由一位看不见的 AI 搭档在后台悄悄完成了——而你更多是在提问题、定方向、做决策,而不是一行行敲代码,这会是什么感觉?是兴奋... 国内服务器 3个月前330