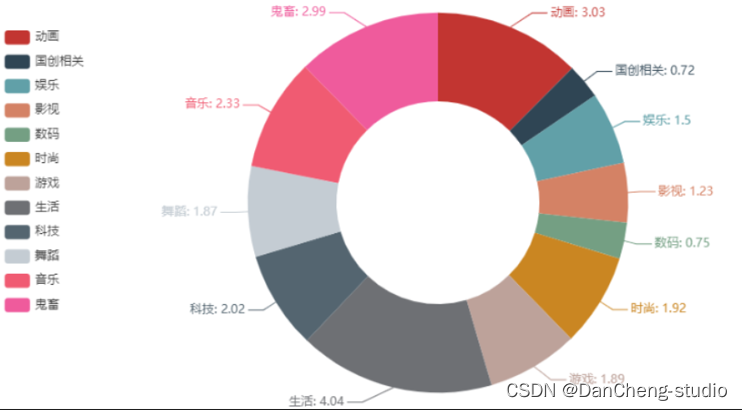
基于大数据的b站数据分析 本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。从数据可视化中可以看到... 国内服务器 2周前90
Internet Archive下载器完整使用指南:3分钟学会批量下载电子书 想要轻松获取Internet Archive和HathiTrust数字图书馆的珍贵电子书资源吗?这款免费浏览器扩展让您一键下载数千页完整书籍,支持PDF导出和图片批量获取,操作简单到极致。无论您是学术... 国内服务器 1周前180
消息队列深度对比:Kafka vs RabbitMQ vs RocketMQ vs Pulsar vs NATS,选型 + 实战 + 性能调优 本文系统对比主流消息队列 Kafka、RabbitMQ、RocketMQ、Pulsar 和 NATS JetStream 的核心差异。从架构设计、功能特性、性能表现到使用场景进行全方位分析,提供生产级... 国内服务器 2周前80
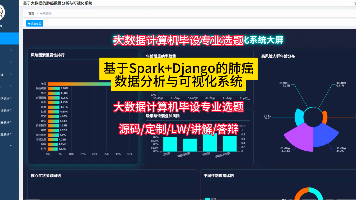
【毕设选题】基于Spark+Django的肺癌数据分析系统,大数据毕设首选 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 为探索肺癌风险因素,本系统构建了基于Spark+Django的数据分析与可视化平台。后端利用Spark对海量肺癌数据进行高效处理,通过人口统计学、行为风险、临床症状等多维度分析,挖掘关键影响因素。Dj... 国内服务器 1周前70
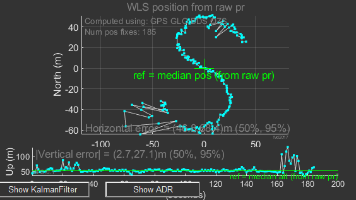
【GNSS】 Android GNSS数据采集入门:GNSSLogger完整配置指南 本文介绍了Android GNSS数据采集工具GNSSLogger的配置与使用方法。主要内容包括:GNSSLogger的功能特点(支持原始GNSS测量、GnssStatus、NMEA等数据记录);设备... 国内服务器 2周前100
数据仓库维度建模:缓慢变化维SCD类型3原理与实战版本控制 缓慢变化维度指业务中不经常变化,但会偶尔发生修改的维度数据,如用户修改手机号、商品调整分类、员工更换部门等。SCD类型3:通过在维度表中增加历史版本字段的方式,分别存储当前值 + 上一个历史值,实现简... 国内服务器 1周前80
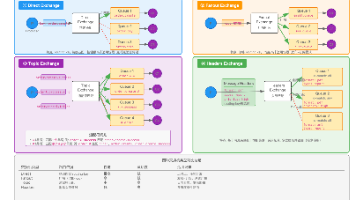
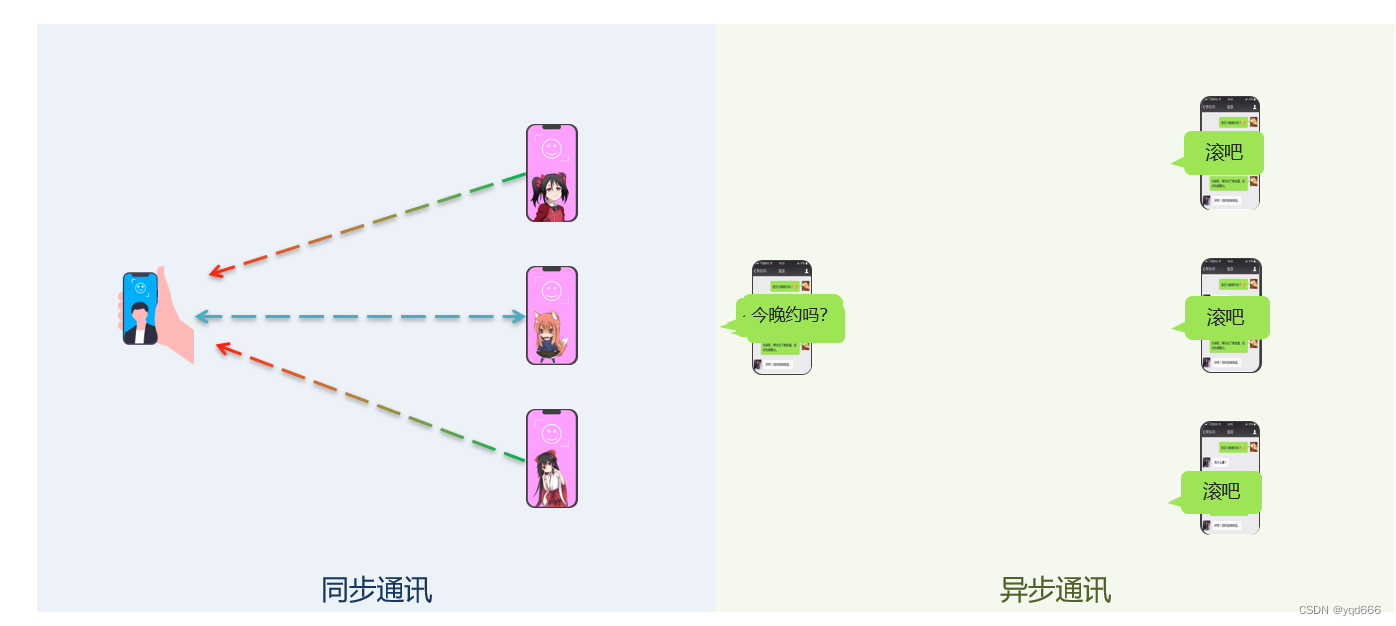
RabbitMQ用法 本文介绍了消息队列(MQ)的核心概念与应用场景,对比了同步通讯和异步通讯的优缺点,并详细讲解了RabbitMQ的安装配置与SpringAMQP的使用方法。 同步vs异步通讯: 同步通讯时效性强但耦合度... 国内服务器 2周前90
[毕设选题] 2025-2026 年 计算机科学与技术专业毕设选题推荐汇总 web应用 / 大数据/人工智能 新颖题目 大全✅ 计算机选题合集涵盖Web应用开发、移动应用开发、数据库与大数据处理、信息安全应用、智能系统开发等五大研究方向的选题指南与实践案例。适合计算机应用技术、软件工程、网络工程等相关专业的本科生做毕业设计参考... 国内服务器 1周前70
RabbitMQ核心技术深度解析 RabbitMQ是一个基于AMQP协议的开源消息代理系统,采用Erlang开发,具有灵活路由、高可靠性等优势。其核心架构包含生产者、交换机、队列和消费者等组件,支持多种交换机类型(Direct、Fan... 国内服务器 2周前180
【开题答辩全过程】以 基于hadoop的空气质量数据分析及可视化系统为例,包含答辩的问题和答案 本文介绍了一位拥有14年经验的毕设指导专家,擅长多种编程语言和技术栈。通过一个基于Hadoop的空气质量数据分析系统的答辩案例,展示了从开题到答辩的全过程。系统采用B/S架构,整合Jsoup爬虫、Ha... 国内服务器 1周前90



![[毕设选题] 2025-2026 年 计算机科学与技术专业毕设选题推荐汇总 web应用 / 大数据/人工智能 新颖题目 大全✅](https://os.v.madlive.cn/idcmadlive/2026/07/9d84e248341a4e1883b3323f1a253598.png)