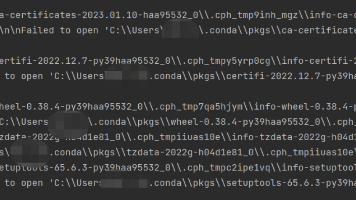
Conda 报错 InvalidArchiveError 深度排查与彻底解决指南:从缓存损坏到环境重建的完整思路 InvalidArchiveError这个看似简单的报错,背后涉及 Conda 的缓存机制、Windows 文件系统、杀毒软件干扰以及包管理工具的实现差异。本文将围绕这一问题展开系统分析,从问题发现... 国内服务器 4个月前890
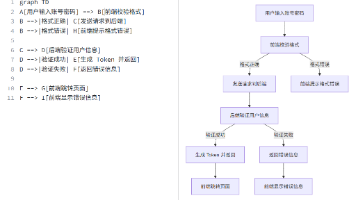
结合 AI 生成 mermaid、plantuml 等图表 AI 画图并不是真的让 AI 画一个图片,而是让 AI 根据你的需求,生成对应的需求文本,再根据 “文本画图” 来生成图片。mermaid 支持流程图、时序图、架构图等等多种图片绘制。当然最终生成的效... 国内服务器 6个月前890
在 NVIDIA DGX Spark部署 Stable Diffusion 3.5 并使用ComfyUI 随着 NVIDIA Blackwell 架构的问世,将桌面级 AI 算力推向了新的巅峰。这台怪兽级设备搭载了GB200/GB10级别的 GPU 和,并运行在最新的CUDA 13环境下。然而,“最强硬件... 国内服务器 6个月前880
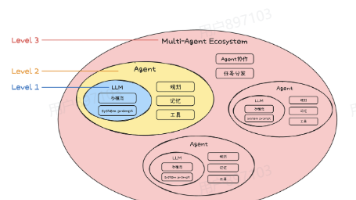
从零开始搞定 AI Agent 搭建全流程 本文系统介绍了AI Agent的生态体系,包括协议标准、思考框架和开发框架三大核心内容。在协议层面,重点分析了面向上下文的MCP协议和面向Agent间协作的A2A协议,阐述了标准化协议在互操作性、可扩... 国内服务器 6个月前880
基于Docker快速搭建Kafka 3.6.1集群(Kraft模式)| 2025最新实战教程 本文详细介绍如何使用Docker Compose在Windows环境下快速搭建高可用的Kafka 3.6.1三节点集群,采用最新的Kraft模式(无需Zookeeper),包含完整的配置文件、网络规划... 国内服务器 6个月前880
30分钟搞定Hadoop3集群搭建 新手30分钟快速搭建Hadoop3节点集群指南 摘要:本文提供零基础新手30分钟内完成Hadoop3节点集群搭建的详细教程。内容包含:1) 环境规划与准备工作,包括节点角色分配、IP规划及JDK安装... 国内服务器 6个月前880
国产化消息中间件双雄:东方通TongLINK/Q与华为RabbitMQ的运维核心技术全解析 本文深入探讨了国产消息中间件在信创产业中的应用,重点分析了东方通TongLINK/Q和华为RabbitMQ国产化适配版两款产品的技术特点与运维要点。文章详细阐述了队列配置、消息路由管理和死信队列处理三... 国内服务器 5个月前870
本地 Kafka 4.0+ 最新版 完整部署教程 + Kafka-UI 可视化 + 项目配置适配(全版本通用,避坑完整版) Kafka-UI 是目前最好用的 Kafka 可视化管理工具,功能全覆盖:创建 / 删除主题、查看生产 / 消费消息、管理消费者组、查看消费偏移量、监控 Kafka 状态等,完全替代繁琐的命令行操作... 国内服务器 6个月前870