Kafka 消息持久化深度解析:从 PageCache 到磁盘的奥秘 消息持久化是指将消息数据保存到非易失性存储介质(如磁盘)中,以确保在系统故障、重启等情况下数据不会丢失。Kafka 的设计哲学之一是"数据不丢失",它将所有消息持久化到磁盘,并提供... 国内服务器 2个月前310
大数据ETL工具比较:Sqoop vs Flume vs Kafka 大数据时代,数据分散在各类数据库、服务器日志、IoT设备中,如何高效“搬运”“整合”数据是分析的第一步。本文聚焦结构化数据迁移、日志收集、实时数据流处理三大典型ETL场景,对比Sqoop、Flume... 国内服务器 3个月前310
《Windows Internals》10.1.20 Hive structure:为什么一个 Hive 在内部不是“键和值的平铺集合”,而是 block、base block、bin、cell 这种 本文解析了Windows注册表Hive的分层存储结构,指出其并非简单的键值平铺集合。Hive内部采用4KB block作为基础存储单元,首个base block存储全局元信息(如regf签名、校验和等... 国内服务器 3个月前310
Stable-Diffusion-v1-5-archive企业合规实践:生成内容水印嵌入+版权元数据自动标注 本文介绍了如何在星图GPU平台上自动化部署stable-diffusion-v1-5-archive镜像,并为企业级应用构建合规解决方案。该方案通过在AI生成的图片中嵌入隐形水印和自动添加版权元数据... 国内服务器 3个月前310
时序数据库选型:聚焦时间序列数据库Apache IoTDB——为工业物联网与大数据而生 摘要:本文系统分析了时序数据库的选型核心要素,对比了InfluxDB、TimescaleDB、VictoriaMetrics和Apache IoTDB等主流产品。时序数据具有时间戳、测量值和标签等特征... 国内服务器 3个月前310
RabbitMQ消息中间件协调多个Miniconda工作节点 通过RabbitMQ实现可靠任务调度,结合Miniconda统一Python执行环境,打造可扩展、高容错的分布式工作节点集群,适用于AI预处理、批量推理等场景,兼顾轻量与企业级需求。 国内服务器 3个月前310
解析大数据领域 Kafka 的日志清理策略 维度Delete 策略Compact 策略核心逻辑过期即删(时间/大小阈值)保留每个 key 的最新版本适用数据类型日志型(流水数据)状态型(key-value 数据)key 要求无要求必须有唯一 k... 国内服务器 3个月前310
【即时通讯项目】环境搭建8——RabbitMQ,AMQP-CPP RabbitMQRabbitMQ 是一个消息中间件,你可以把它理解成一个专门负责接收、存储和转发消息的程序。它让不同的软件系统或者同一个系统的不同模块之间可以相互通信,但不需要直接连接对方。它的工作方... 国内服务器 3个月前310
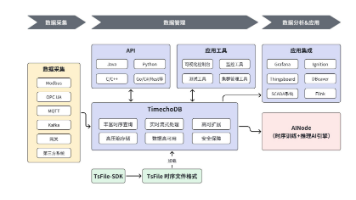
【数据库】时序数据库选型指南:从大数据视角看 Apache IoTDB 的跨“端 – 边-云”架构优势 摘要 在物联网时代,时序数据管理面临写入性能、存储效率和查询分析等挑战。Apache IoTDB作为专为工业物联网设计的时序数据库,通过独特的树表孪生模型实现高效数据管理:树模型贴合设备层级关系,优化... 国内服务器 3个月前310
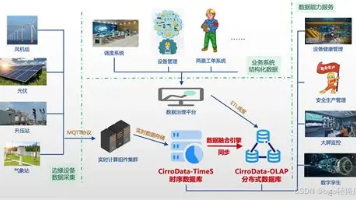
2026时序数据库选型全指南:大数据场景下的国产最优解,IoTDB实力领跑 随着工业物联网、智慧城市等领域时序数据爆发式增长,时序数据库成为大数据架构核心组件。本文提出时序数据库选型六大维度:高吞吐写入、高效存储压缩、快速查询、轻量化扩展、生态兼容及本土化服务。重点推荐国产开... 国内服务器 3个月前310