C#高性能RabbitMQ帮助类设计与实现 你看,一个看似简单的消息队列,背后竟然有这么多门道。从 AMQP 协议理解,到连接池优化;从交换机选型,到死信队列设计;再到断线重连、结构化日志、性能压测……每一个环节都关系到系统的稳定性与可维护性... 国内服务器 3个月前320
大数据领域核心 SQL 优化框架Apache Calcite介绍 Apache Calcite是一个开源的动态数据管理框架,专注于SQL解析、关系代数转换和查询优化。作为大数据领域SQL处理的"编译器内核",它被Flink、Hiv... 国内服务器 3个月前330
HiveSQL 中的集合运算详解 摘要:本文详细介绍了HiveSQL中的集合运算方法及其应用场景。重点讲解了UNION/UNIONALL(数据合并)、INTERSECT(交集)和EXCEPT(差集)三大核心运算符的使用技巧和性能优化策... 国内服务器 3个月前270
探索大数据领域Hadoop的分布式计算框架 在当今数字化时代,数据量呈现出爆炸式增长,传统的数据处理技术已经难以满足对海量数据进行高效存储和快速处理的需求。Hadoop作为一个开源的分布式计算框架,应运而生。本文章的目的在于全面深入地探索Had... 国内服务器 3个月前290
MapReduce与Kafka实时数据处理 本文从“批处理的局限性”入手,介绍了Kafka的实时性优势,然后通过架构设计和实战,实现了Kafka+MapReduce的实时数据处理。核心要点回顾MapReduce:擅长大规模批处理,但延迟高;Ka... 国内服务器 3个月前300
【JAVA探索之路】简单聊聊Kafka 它提供了高级的DSL和低级的Processor API,支持窗口、连接、聚合等复杂操作,并与Kafka的状态存储紧密集成,实现有状态的、容错的流处理。从各种源头(应用日志、数据库变更、传感器)收集数据... 国内服务器 3个月前270
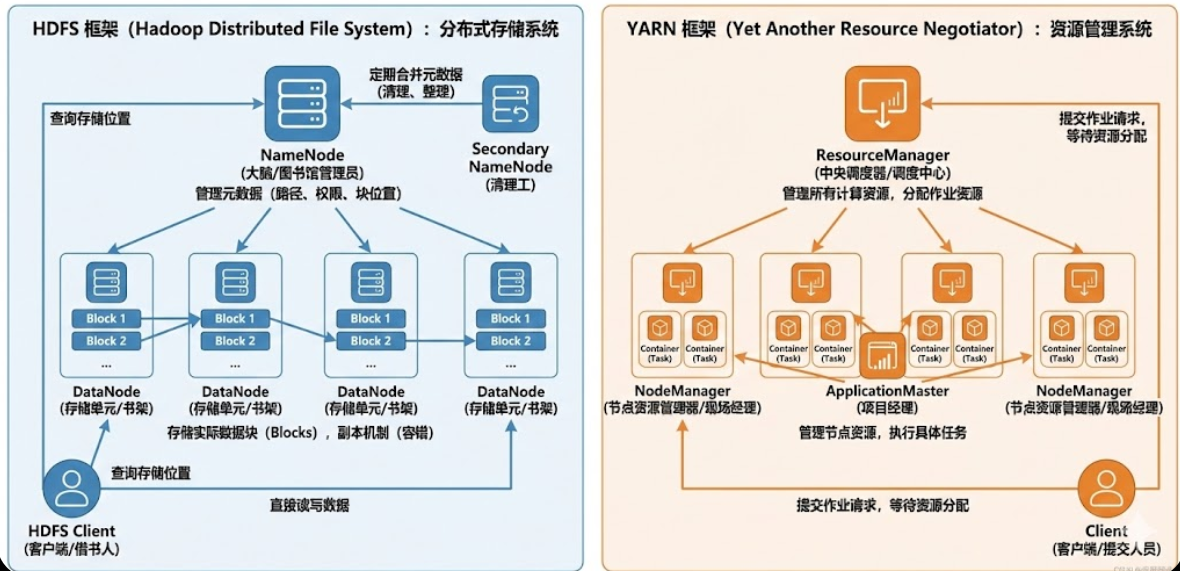
hadoop中HDFS框架、YARN框架各组件职责与对比 简而言之,HDFS 和 YARN 各自担任不同的角色。HDFS 作为存储系统,负责数据的分布式存储和管理,确保数据的高可用性;而 YARN 作为资源管理系统,负责调度和管理集群资源,确保作业能够高效执... 国内服务器 3个月前310
Ubuntu20.04搭建Hadoop大数据生态——从零开始:Ubuntu 20.04 搭建Hadoop+Hive+HBase+Spark大数据平台全攻略 本教程详细介绍了在Ubuntu 20.04系统上搭建Apache Hadoop大数据生态平台的完整流程。内容包括HDFS、YARN、Hive、HBase和Spark的安装配置,重点讲解了版本兼容性选择... 国内服务器 3个月前330
Kafka Partition 深度解析:数据分片的艺术与性能之舞 Partition(分区)是 Kafka 中消息的物理存储单元。每个 Topic 可以被划分为多个 Partition,每个 Partition 是一个有序的、不可变的消息序列,并以日志文件的形式存储... 国内服务器 3个月前380
hive旅游数据分析与应用 abo信息管理系统源码-SpringBoot后端+Vue前端+MySQL【可直接运行】 直接拿走,意外获得200多套代码,需要的滴我hive旅游数据分析与应用 abo信息管理系统源码-SpringBoot后端+Vue前端+MySQL【可直接运行】(可提供说明文档(通过*AIGC*) 国内服务器 3个月前280