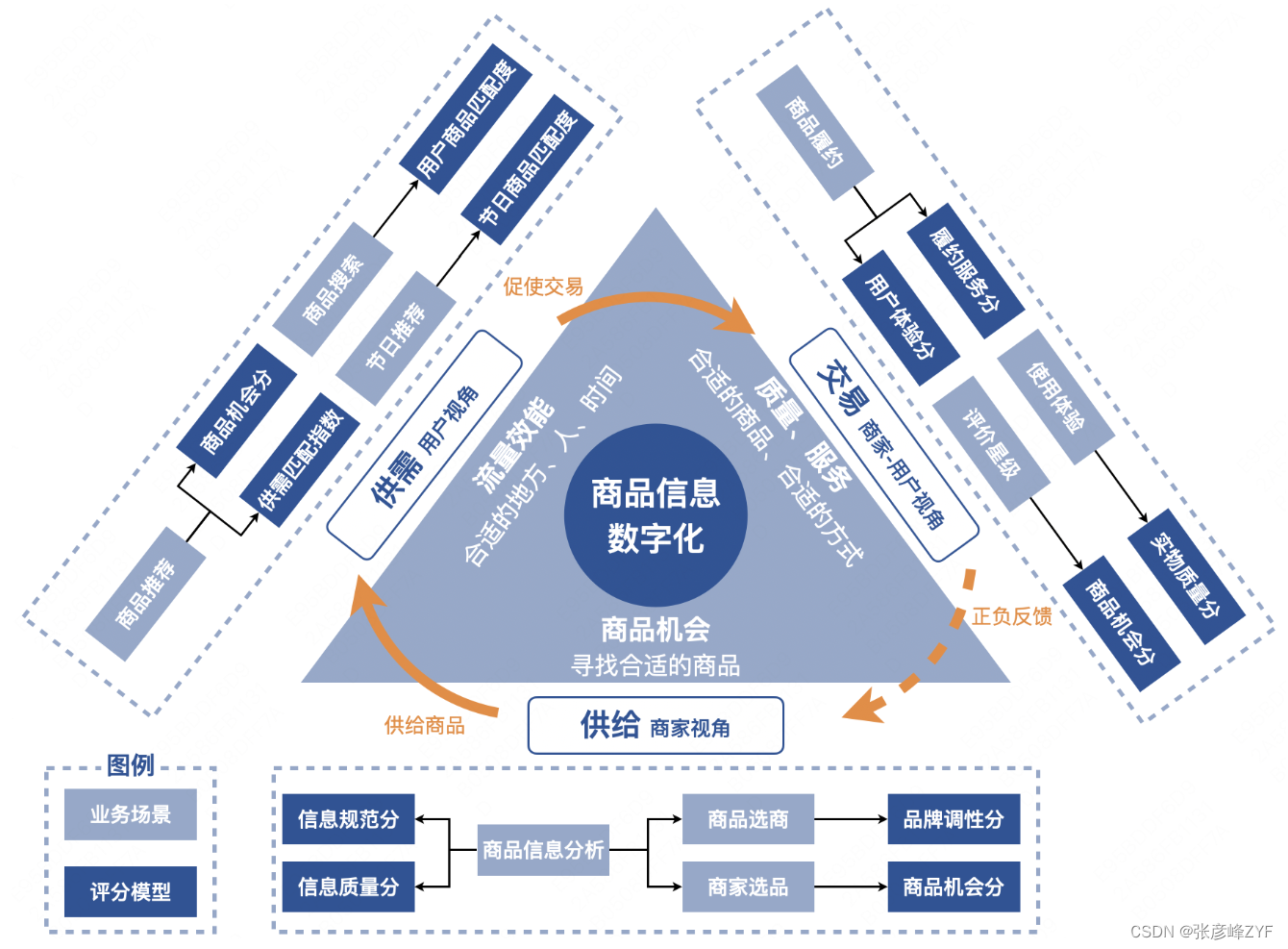
互联网数字化商品管理浪潮思考:从信息化到精准运营 从技术角度来看,从运营百万商家到管理数十亿商品,平台必须依靠数据化手段进行商品管理。通过数据化重构人、货、场的关系,优化流量分配和精准营销,使数据成为连接商业环节的最佳语言,最终提升平台的整体流量价值... 国内服务器 3个月前310
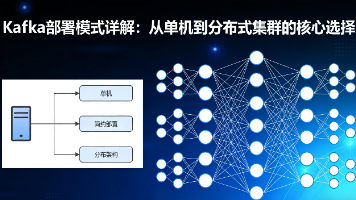
Kafka部署模式详解:从单机到分布式集群的核心选择 Kafka部署模式没有"最好",只有"最合适"。选择的关键在于深刻理解业务需求与技术约束的平衡点。初创验证期:单机部署快速起步业务成长期:主备部署平衡可靠性与成... 国内服务器 4个月前310
大数据领域使用ClickHouse的常见问题及解决方案 ClickHouse作为一款开源的列式OLAP数据库管理系统,因其卓越的查询性能在大数据领域获得了广泛应用。然而,在实际生产环境中,用户常常面临各种技术挑战和性能瓶颈。本文旨在系统性地梳理这些常见问题... 国内服务器 4个月前310
Java 大视界 — Java 大数据在智能教育学习社区互动模式创新与用户活跃度提升中的应用(426) 本文探讨了Java大数据技术在智能教育学习社区中的应用,如何通过精准匹配用户需求提升互动效率和活跃度。文章指出传统教育社区存在响应滞后、匹配偏差和参与门槛高等痛点,导致用户活跃度低。通过Java大数据... 国内服务器 4个月前310
java-分布式面试题(事务+锁+消息队列+zookeeper+dubbo+nginx+es) 单个服务的单一数据库事务通过代码控制 实现 事务问题通过 本地消息表(其实类似于一个协调者) 和 MQ 实现最终一致性【rabbitMQ也支持事务,但是性能差】rocketMQ支持事务,通过其半消息实... 国内服务器 4个月前310
量讯物联携HiveLink云宽带亮相CHIC,助力连锁零售数字化降本增效 量讯物联亮相CHIC中国国际服装博览会,推出HiveLink蜂行速联™云宽带解决方案,助力服装零售行业数字化转型。该产品针对连锁门店网络部署成本高、运维复杂等痛点,提供智能管理、成本优化、灵活部署和稳... 国内服务器# 联通 2个月前300
Blue Archive自动脚本:从零开始的完整使用指南 作为一款专为热门手游《Blue Archive》(蔚蓝档案)开发的自动化辅助工具,Blue Archive自动脚本通过计算机视觉和自动化技术,帮助玩家自动完成游戏中的各种重复性任务,从资源收集到活动挑... 国内服务器 2个月前300
Fate未来展望:AI与大数据如何重塑中文姓名生成 在传统文化与现代科技交融的今天,中文姓名生成工具正经历着前所未有的变革。Fate作为GitHub上第一个开源的中文取名项目,以「现代科学取名工具」为定位,正在探索AI与大数据技术如何为姓名生成注入新活... 国内服务器 2个月前300
StarRocks:高性能分析型数据仓库 StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过... 国内服务器 2个月前300
基于Spark的大规模数据集成处理实战教程 在数字化时代,企业数据像“爆炸的烟花”——来源多(日志、数据库、IoT设备)、格式杂(CSV/JSON/关系表)、规模大(TB级甚至PB级)。传统工具(如Python脚本、Excel)处理这类数据时... 国内服务器 2个月前300