基于Spark的大规模数据集成处理实战教程 在数字化时代,企业数据像“爆炸的烟花”——来源多(日志、数据库、IoT设备)、格式杂(CSV/JSON/关系表)、规模大(TB级甚至PB级)。传统工具(如Python脚本、Excel)处理这类数据时... 国内服务器 2个月前300
在DGX-Spark上多模态模型gemma-4-31B-it vLLM部署 显存优化fp8量化 + 70% 显存限制 + 分块预填充,适合大模型部署性能优化:前缀缓存 + SafeTensors 格式,提升重复查询和加载速度功能特性:支持工具调用(Tool Calling)和... 国内服务器 2个月前300
从调度到实时:Linux 下 DolphinScheduler 驱动 Flink 消费 Kafka 的实战指南 是指挥官。负责 Flink 作业的提交(Submit)。负责作业的启停控制负责依赖管理(例如:只有当 Kafka 集群健康或前置 ETL 完成后,才启动 Flink)。负责告警与监控(作业失败重试、延... 国内服务器 3个月前300
Flink CDC与Debezium的共生关系:从技术融合到性能优化 本文深入探讨了Flink CDC与Debezium的技术融合与性能优化,构建高性能实时数据管道的实践方法。通过分析两者的共生关系、核心特性实现原理及性能调优策略,展示了如何利用Streaming EL... 国内服务器 3个月前300
大数据领域数据预处理的质量评估指标 数据预处理是大数据项目中最耗时且关键的环节,据统计,数据科学家80%的时间都花费在数据清洗和预处理上。本文旨在系统性地介绍数据预处理阶段的质量评估指标体系,帮助读者建立科学的数据质量评估框架。核心概念... 国内服务器 3个月前300
Spark RDD深度解析:The Definitive Guide低阶API使用手册 Apache Spark RDD(弹性分布式数据集)是Spark大数据处理框架的核心抽象,也是理解Spark分布式计算模型的基石。本文将基于Spark The Definitive Guide官方代码... 国内服务器 3个月前300
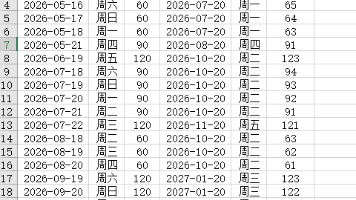
【理财类-01-04】20260321“微信”定期60天、90天、120天,倒退计算最适合买入的日期,在每月8日和每月20日准时到账还款(与理财系统一致) 【理财类-01-04】20260321“微信”定期60天、90天、120天,倒退计算最适合买入的日期,在每月8日和每月20日准时到账还款(与理财系统一致) 国内服务器 3个月前300
SAP Ariba | EDI 传输:名称/单号被截断了怎么办? SAP系统中常出现供应商名称或订单号在EDI传输时被截断的问题,主要原因是主数据字段与EDI/IDoc结构的长度限制不匹配(如REGUH表仅支持35字符)。解决方案包括:拆分长名称到NAME2字段(N... 国内服务器 3个月前300
Flink 内存与容器异常排障从报错关键词到精准下药 本文总结了 Flink 常见的内存异常类型及解决方案,包括: 配置异常:检查内存值合法性、fraction范围和min/max逻辑 堆内存不足:增加总内存或精准调整堆大小 直接内存不足:提高direc... 国内服务器 3个月前300
claude-code-best-practice高级技巧:如何构建自定义技能与工作流优化 claude-code-best-practice是一个专注于提升Claude使用效率的实践项目,通过构建自定义技能和优化工作流,帮助用户充分发挥Claude的强大功能。本文将分享构建自定义技能与工作... 国内服务器 3个月前300