RabbitMQ – 内存配置优化:内存限制与换页机制调整 RabbitMQ 内存优化实践总结 本文深入探讨了 RabbitMQ 的内存管理机制和优化策略,主要内容包括: 内存基础配置 默认使用系统40%内存 支持绝对值和百分比两种配置方式 可通过配置文件、环... 国内服务器 3个月前300
【大数据毕设全套源码+文档】基于django+深度学习的淘宝用户购物可视化与行为预测系统设计(丰富项目+远程调试+讲解+定制) 主要内容:免费开题报告、任务书、全bao定制+中期检查PPT、代码编写、🚢文编写和辅导、🚢文降重、长期答辩答疑辅导、一对一专业代码讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。 国内服务器 3个月前300
《数据治理实战指南》—【第三部分 实施篇】第7章 数据仓库及数据模型管理 数据仓库是为更好地分析和处理数据,面向主题来组织数据的存储系统。数据模型是定义数据结构、关系与规则的蓝图,是数据仓库的架构基础。数据模型决定了数据的组织逻辑与存储规范,数据仓库则是该模型的具体物理实现... 国内服务器 3个月前300
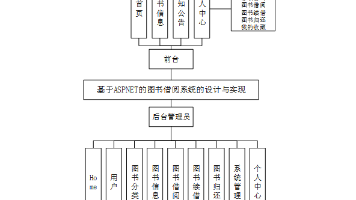
【C#图书借阅系统】(免费领源码+演示录像)|可做计算机毕设Java、Python、PHP、小程序APP、C#、爬虫大数据、单片机、文案 图书借阅系统主要包括了前端net技术,后端vue框架技术的开发,数据库的建立和后台管理员的管理,并且采用 net语言进行开发,使用SQLServer数据库存储相关的数据。从而实现了图书借阅管理的相关功... 国内服务器 3个月前300
ClickHouse OLAP 数据仓库在互联网大规模分析场景下性能优化与查询加速实践经验分享 通过 ClickHouse OLAP 系统优化实践,可以在大规模互联网业务中实现:PB 级数据实时分析毫秒级查询响应热点数据自动缓存加速副本与多活机制保证高可用批量写入与分区策略提高吞吐全链路监控与资... 国内服务器 3个月前300
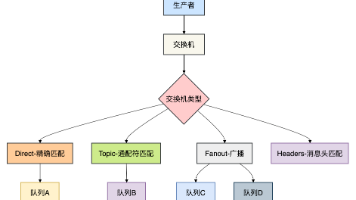
RabbitMQ和RocketMQ,哪个更好? 最近有球友问我:苏三哥,现在一般的项目中的消息中间件,是用RabbitMQ,还是RocketMQ,更好?这是一个非常常见的问题。今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。Rabbi... 国内服务器 3个月前300
【Kafka基础篇】搞懂Kafka架构不用死记硬背:Topic与Partition映射逻辑一文讲透 Kafka作为分布式消息队列的核心组件,其架构围绕Producer、Broker、Consumer三大核心模块协作实现高吞吐、高可用。Producer负责消息发送,支持分区选择、批量发送和重试机制;B... 国内服务器 3个月前300
Hadoop网络通信性能调优深度指南:从原理到实战 fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;height:1... 国内服务器 3个月前300
HiveSQL 中的集合运算详解 摘要:本文详细介绍了HiveSQL中的集合运算方法及其应用场景。重点讲解了UNION/UNIONALL(数据合并)、INTERSECT(交集)和EXCEPT(差集)三大核心运算符的使用技巧和性能优化策... 国内服务器 3个月前300
【JAVA探索之路】简单聊聊Kafka 它提供了高级的DSL和低级的Processor API,支持窗口、连接、聚合等复杂操作,并与Kafka的状态存储紧密集成,实现有状态的、容错的流处理。从各种源头(应用日志、数据库变更、传感器)收集数据... 国内服务器 3个月前300