Python大数据毕设选题:基于Hadoop+Django肥胖风险分析与可视化系统详解 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 本项目设计并实现了一个基于Hadoop+Django的肥胖风险分析与可视化系统。系统利用HDFS存储海量健康数据,通过Spark核心计算引擎,对人口统计学、饮食习惯及生活方式等多维度数据进行高效处理与... 国内服务器 3个月前330
大数据领域Zookeeper的集群配置自动化工具推荐 在大数据生态中,Zookeeper作为分布式系统的"协调大脑",其集群配置的可靠性直接影响Hadoop、HBase、Kafka等核心组件的稳定性。然而手动配置Zookeeper集群... 国内服务器 3个月前380
Spark 中 distribute by、sort by、cluster by 深度解析 管“数据分到哪”(Shuffle 分区),sort by管“分区内怎么排”(局部排序),cluster by是二者的简化版(同字段);实现本质:三者均依赖 Spark Shuffle 机制,差异仅在... 国内服务器 3个月前360
2026 AI 全景图谱:从底层大模型到全自动 Agent 编程 在 AI 爆发式增长的今天,开发者和企业常被层出不穷的名词包围。本文将从底层模型、算力平台、编程形态及生态中转四个维度,为您梳理当前最权威的 AI 技术版图。 国内服务器# kimi 3个月前400
Zookeeper、Hadoop、Hive、Spark、Presto配置Kerberos 本文介绍了Kerberos认证系统在Hadoop集群中的部署与应用。Kerberos通过KDC(票据发放中心)解决企业级安全两大问题:细粒度服务访问控制和凭证有效性验证。部署过程包括:1)准备4台服务... 国内服务器 3个月前970
Docker部署Hadoop+Flink集群 本文介绍了使用Docker部署Hadoop和Flink集群的详细过程。作者基于CentOS镜像构建了包含SSH、JDK和Hadoop的基础镜像,创建了三台容器组成Hadoop集群。通过自定义Docke... 国内服务器 3个月前290
无zookeeper Kafka 4.1.0 Raft 集群搭建 实现高可用,集群若允许N个controller失败,则需要2N+1个controller组成集群。下面搭建一个3节点的Kafka集群,3个controller,3个broker。Kafka kraft... 国内服务器 3个月前310
大数据毕设选题推荐:基于springboot+数据可视化的智能农业管理系统【附源码、mysql、文档、调试+代码讲解+全bao等】 主要内容:免费开题报告、任务书、全bao定制+中期检查PPT、代码编写、🚢文编写和辅导、🚢文降重、长期答辩答疑辅导、一对一专业代码讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。 国内服务器 3个月前300
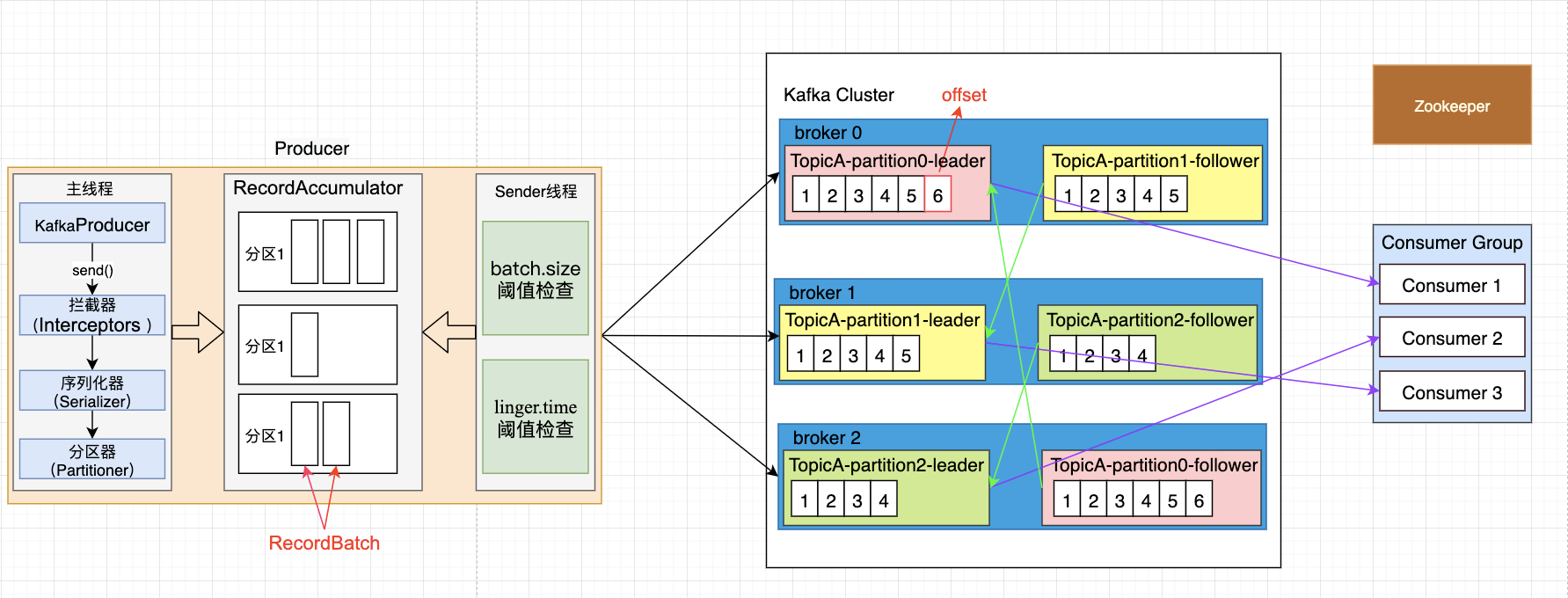
Kafka 深度详解 核心组件包括 Producer(生产者,发送消息)、Consumer(消费者,消费消息)、Broker(服务节点,存储和处理消息)、Topic(主题,消息逻辑分类)、Partition(分区,物理存储... 国内服务器 3个月前260

![[C++][第三方库][RabbitMq]详细讲解](https://os.v.madlive.cn/idcmadlive/2026/03/b243bc25ff10408a872764c01a2dbf33.png)