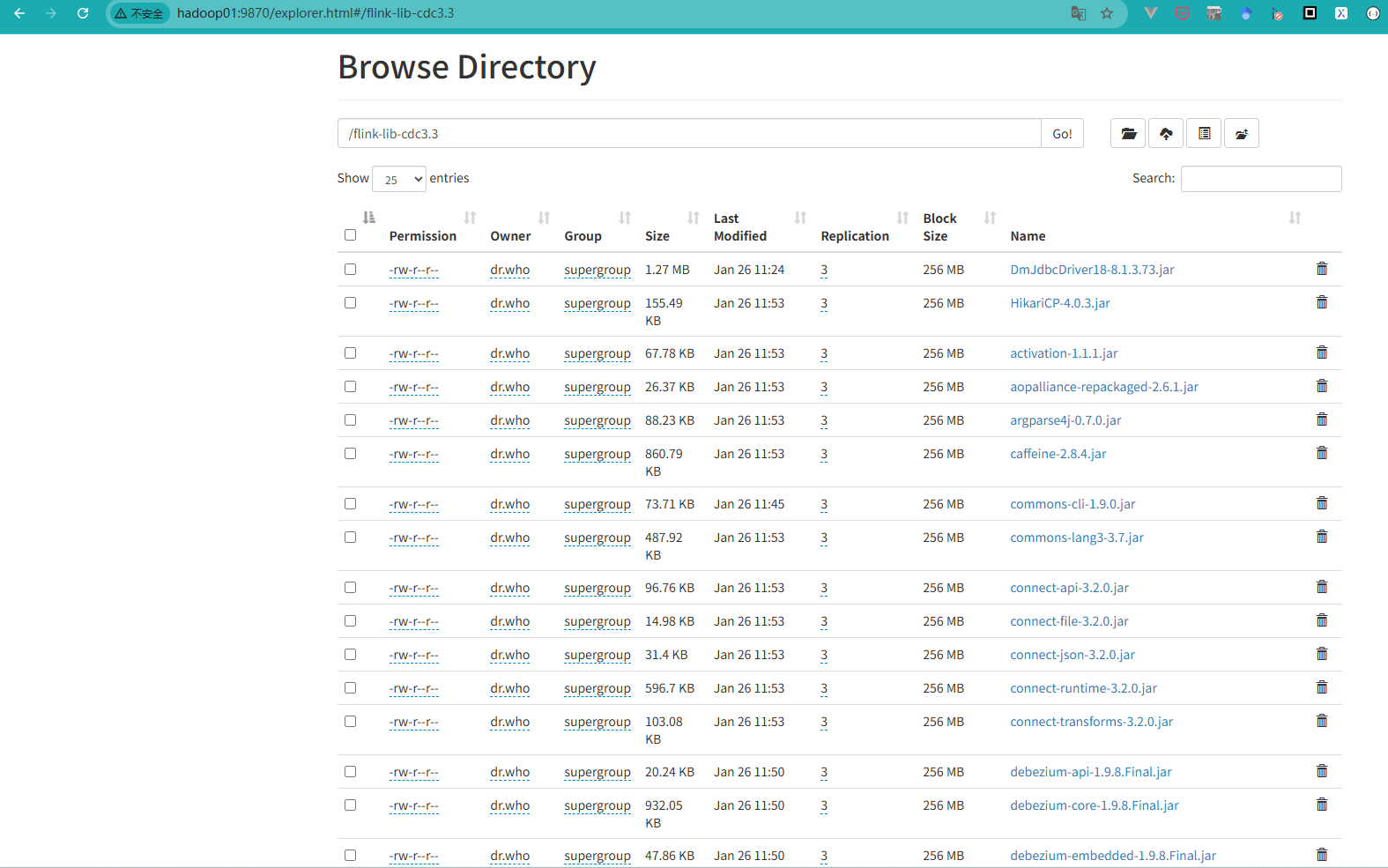
Dinky+Flink SQL达梦数据库实时同步到Doris简单实现 请看官网:https://doris.apache.org/zh-CN/docs/3.x/install/deploy-manually/integrated-storage-compute-depl... 国内服务器 2个月前270
Java 大视界 — Java 大数据在智能医疗医疗设备维护与管理中的应用(358) 本文结合 21 个医院案例,详解 Java 大数据在医疗设备维护管理中的应用。故障预警提前至 72 小时,维修费用降 60%,附完整代码与智能派单方案,提升设备运行稳定性。 国内服务器 2个月前270
RabbitMQ – 消费者线程池配置:提升并发消费能力 本文探讨了RabbitMQ消费者线程池配置的关键策略,通过多线程并行处理提升消息消费能力。主要内容包括: 消费者线程池的必要性:单线程处理成为性能瓶颈,无法充分利用系统资源 基础概念回顾:Connec... 国内服务器 2个月前270
RabbitMQ 死信队列(DLX)全面解析:是什么、工作流程、应用场景与实战配置 在 RabbitMQ 实际生产环境中,消息消费失败、消息过期、队列溢出是非常常见的问题。如果这些消息不做处理,就会导致业务数据丢失、系统异常。而**死信队列(DLX)**就是专门用来解决这类问题的核心... 国内服务器 2个月前270
Linux驱动开发中probe函数的设备树匹配机制解析 本文深入解析Linux驱动开发中probe函数的设备树匹配机制,重点探讨I2C总线下的设备注册与驱动匹配流程。通过compatible属性实现硬件与驱动的智能匹配,详细讲解of_match_table... 国内服务器 2个月前270
大数据领域特征工程:数据预处理的艺术 数据预处理的本质是将原始数据转化为适合模型输入的格式清洗脏数据:处理缺失值、异常值、重复值,解决数据不一致问题;转换数据格式:将非数值型数据(如文本、日期)转换为数值型,统一特征尺度;减少数据冗余:通... 国内服务器 2个月前270
大数据专业毕设论文效率提升指南:从数据管道到自动化分析的实战优化 通过以上这套组合拳——清晰的项目结构、模块化的PySpark代码、灵活的配置管理、以及自动化的报告流程,我在自己的毕设开发中,将后期重复性工作的效率提升了远不止40%。这让我有更多时间去思考模型优化... 国内服务器 2个月前270
Flink在大数据领域的应用场景全解析 在大数据领域,“实时性”已从“加分项”变为“刚需”:电商需要实时推荐、金融需要实时风控、物联网需要实时监控设备状态……传统的Hadoop批处理(每天处理一次数据)已无法满足需求。本文将聚焦Apache... 国内服务器 2个月前270
【大数据分析 | 深度学习】在Hadoop上实现分布式深度学习 本文介绍大数据和深度学习结合之路,即在Hadoop上实现分布式深度学习。主要讲解三个框架,包括Submarine(Hadoop生态系统),TonY(LinkedIn)和DL4J(deeplearnin... 国内服务器 2个月前270
WinCC8.1利用Microsoft Web Browser控件制作报表 本文介绍了使用MicrosoftWebBrowser控件实现数据库报表查询和导出的完整流程。主要内容包括:1)日报表显示详细数据,月报表取每日平均值;2)通过添加WebBrowser控件和时间控件构建... 国内服务器 2个月前270