Flink原理与实战(java版)#第11章Flink的应用(第三节Table & SQL 连接器之Hive(五)) 介绍Hive作为Table API和SQL的外部连接器使用,并且结合实际应用中会使用kafka作为数据源进行介绍。 国内服务器 2个月前130
【Redis合集-06】生产级Redis分布式锁深度解析:Redisson原理、看门狗与Lua源码实战及ZooKeeper选型对比 在分布式系统中,如何保证跨 JVM 的线程安全是一个高频且棘手的问题。本文从最基础的 setnx 方式入手,深入分析其死锁、误删、不可重入等缺陷,并一步步推导出 Redisson 在生产中落地的完整方... 国内服务器 2周前120
微服务与ZooKeeper:深入解析服务协调的必要性与替代方案 微服务架构中,ZooKeeper作为分布式协调工具,在服务发现、配置管理等场景具有重要作用,但并非必选项。本文系统分析了ZooKeeper的核心原理、典型应用场景及优缺点,对比了Eureka、Cons... 国内服务器 2周前120
基于 Hadoop 3.4.2 部署与问题排查(附企业级场景落地) 摘要 本文基于 Hadoop 3.4.2 版本(2025 年 8 月发布),详细介绍了 HDFS 的最新特性、部署方法及企业级应用场景。主要内容包括: HDFS 3.4.2 核心升级:支持 DataN... 国内服务器 3周前120
AI 辅助开发实战:面向计算机大数据专业本科毕设选题的智能选题与原型生成系统 通过这个AI辅助选题系统的实践,我最大的体会是:工具的意义在于放大人的能力,而不是取代人的思考。它帮我快速穿越了信息的迷雾,看到了更多可能性。但它给出的每一个答案,都是一个起点,而不是终点。用这个思路... 国内服务器# Langchain 3周前120
Flink Trace Reporters 实战配置模型、过滤规则、OpenTelemetry 落地与避坑 本文介绍了Flink的Trace Reporter工作机制及配置方法。Trace Reporter通过插件方式加载,负责将运行时产生的spans输出到外部系统。所有Reporter共享traces.r... 国内服务器 3周前120
Kafka 消息队列在大数据数据采集方面的应用 本文旨在全面解析Kafka作为消息队列在大数据数据采集中的应用场景和技术实现。我们将涵盖从基础概念到高级应用的完整知识体系,包括架构设计、性能优化和实际案例。介绍Kafka核心概念及其在大数据采集中的... 国内服务器 3周前120
Apache Parquet实战:大数据列式存储最佳实践指南 随着数据规模爆炸式增长,传统行式存储在大规模数据分析场景下暴露出IO效率低、计算资源浪费等问题。Apache Parquet作为高性能列式存储格式,通过数据压缩、向量化处理、复杂数据类型支持等特性,成... 国内服务器 3周前120
应届生求职焦虑?高职大数据专业这条“数据分析+“路,起薪突破7000+ 在数据驱动决策的时代,高职生完全可以通过精准规划实现职业逆袭。CDA证书作为行业敲门砖,配合扎实的项目经验,能将应届生求职的“焦虑”转化为“机遇”。抓住未来3年大数据人才红利期,起薪7000+仅是职业... 国内服务器 3周前120
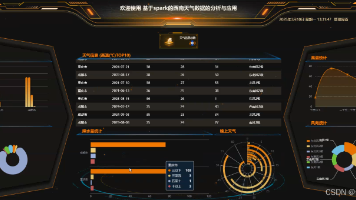
基于Spark+爬虫+Echarts的地区天气数据分析系统设计与实现 今天带来的是基于Spark+爬虫+Echarts的西南天气数据分析系统设计与实现,本研究基于Spark大数据技术,对西南地区气象数据进行多维度分析。通过Python爬虫采集多源气象数据,利用Spark... 国内服务器 3周前120