破解大数据密码:蓝耘Maas平台与阿里QWQ的智能分析革命 蓝耘Maas平台阿里QWQ是基于阿里云的机器学习平台,专注于数据处理、模型训练、实时分析和智能决策。它集成了强大的自然语言处理(NLP)、大数据分析、自动化机器学习等功能,帮助企业和开发者在云端轻松构... 国内服务器 5个月前500
Windows安装RabbitMQ保姆级教程(图文详解) 本教程详细介绍了在Windows系统上安装RabbitMQ的完整流程,从准备工作开始,依次完成了Erlang环境的下载安装和环境变量配置、RabbitMQ服务器的下载安装和配置、服务验证、管理界面启用... 国内服务器 5个月前500
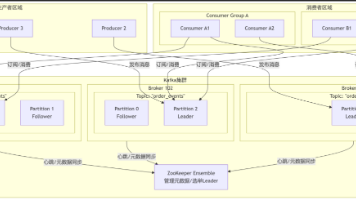
【深度解析】Apache Kafka:驾驭海量数据流的引擎(附图解与代码) Apache Kafka深度解析与实战指南 摘要:本文深入剖析Apache Kafka分布式流平台的核心架构与工作原理。通过图解展示了Topic分区、副本机制、生产者路由策略和消费者组负载均衡等关键设... 国内服务器 5个月前500
数据湖的崛起:从大数据到智能未来的钥匙 随着2025年数据湖技术的成熟,企业正通过这一新型架构解锁海量数据的价值。本文将深入解析数据湖的技术核心、行业应用与中国市场实践,探讨其如何成为AI时代的核心引擎。 国内服务器 5个月前500
ArchivePasswordTestTool完整指南:快速找回压缩包密码的终极解决方案 在数字资产管理日益重要的今天,加密压缩包已成为保护敏感数据的常用手段。然而,密码遗忘问题却时常困扰着用户,导致重要文件无法访问。ArchivePasswordTestTool作为基于7zip引擎的自动... 国内服务器 5个月前500
RabbitMQ直接查看队列中消息的内容 方法是否可看内容是否影响队列用途❌❌查看队列状态✅✅(会消费)小量调试临时消费者脚本✅❌(不 ack)安全调试镜像队列观察✅❌生产调试插件工具✅⚠️不推荐实验性。 国内服务器 5个月前500
SpringBoot项目整合Zookeeper常见错误总结 本文总结了Zookeeper和Dubbo集成中的常见问题及解决方案,包括: 依赖配置问题:如缺少Zookeeper、Curator或Dubbo依赖,提供正确依赖版本; 连接配置错误:包括Zookeep... 国内服务器 5个月前500
libarchive: 一个几乎可以解压所有压缩文件的C语言库 libarchive 是跨平台开源 C 库(BSD 协议,可免费商用),原生支持解压 / 创建 tar、tar.gz、tar.bz2、tar.xz、zip、7z、rar(仅解压)等几乎所有主流压缩格式... 国内服务器 3个月前490
vue3+element-plus实现虚拟列表来解决大数据的问题 当我们列表数据特别多的时候,往往会带来卡顿与性能问题,按我们之前的逻辑,都是通过虚拟列表的方式来实现,现在在使用element后,他的vue3版本最新新增的功能本身就有虚拟列表,给我们带来了极大的便利... 国内服务器 4个月前490
大数据领域存算分离:数据湖建设的关键支撑 本文旨在全面解析存算分离架构在大数据领域,特别是数据湖建设中的应用价值和技术实现。存算分离的基本概念和演进历程数据湖架构的核心组件和设计原则存算分离如何解决传统大数据架构的痛点主流技术实现方案和最佳实... 国内服务器 3个月前490