Spark+Flask新能源车数据分析与推荐系统实战:从0到1搭建完整项目 本次项目以Spark为核心完成新能源车数据的分布式分析,利用Flask搭建Web服务,结合协同过滤算法实现了个性化推荐,覆盖了数据处理、算法实现、Web开发全流程;项目代码可直接复用,通过调整数据集和... 国内服务器 5个月前470
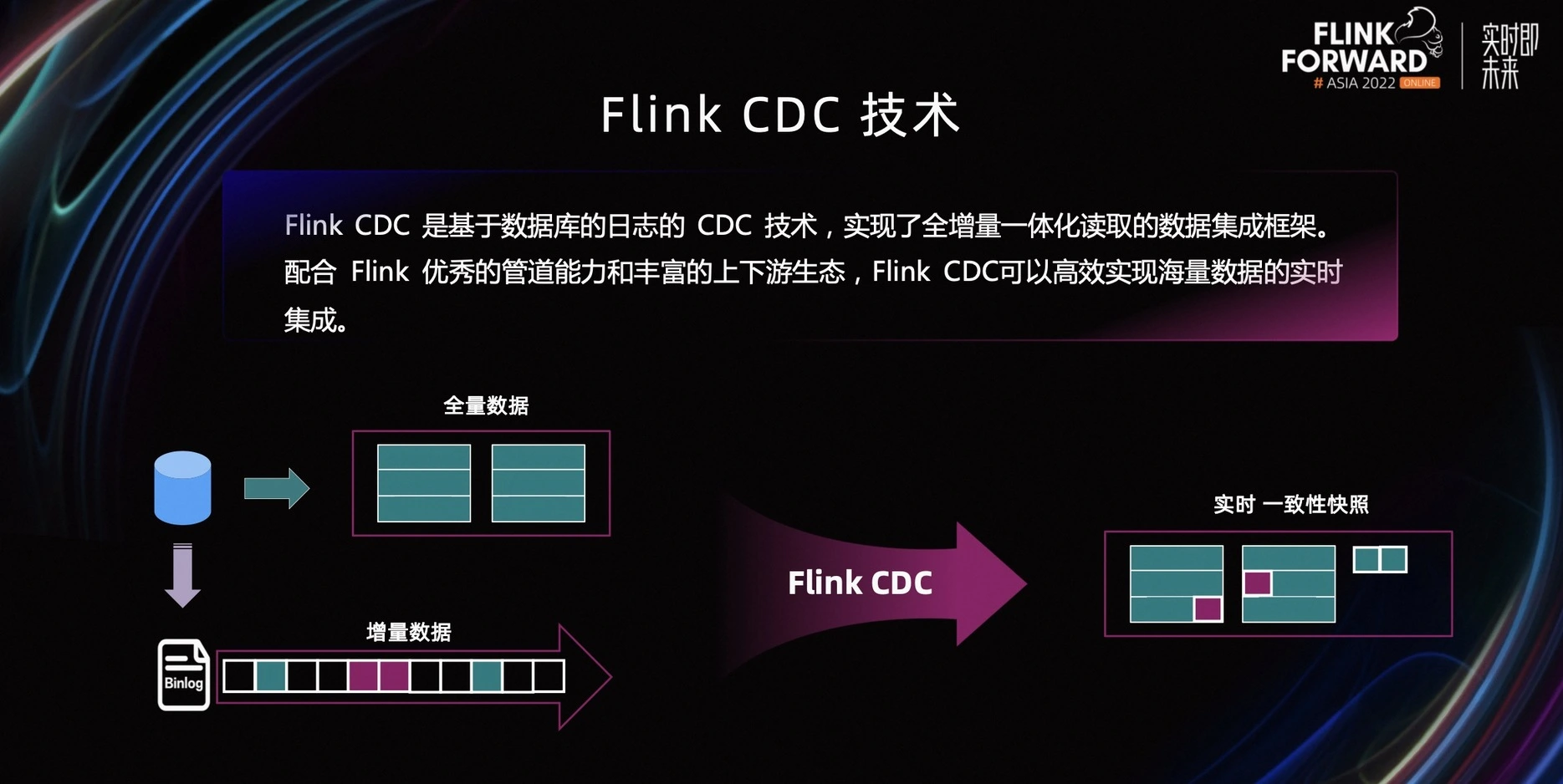
【微服务】springboot3 集成 Flink CDC 1.17 实现mysql数据同步 springboot3 集成 Flink CDC 1.17 实现mysql数据同步 国内服务器 5个月前470
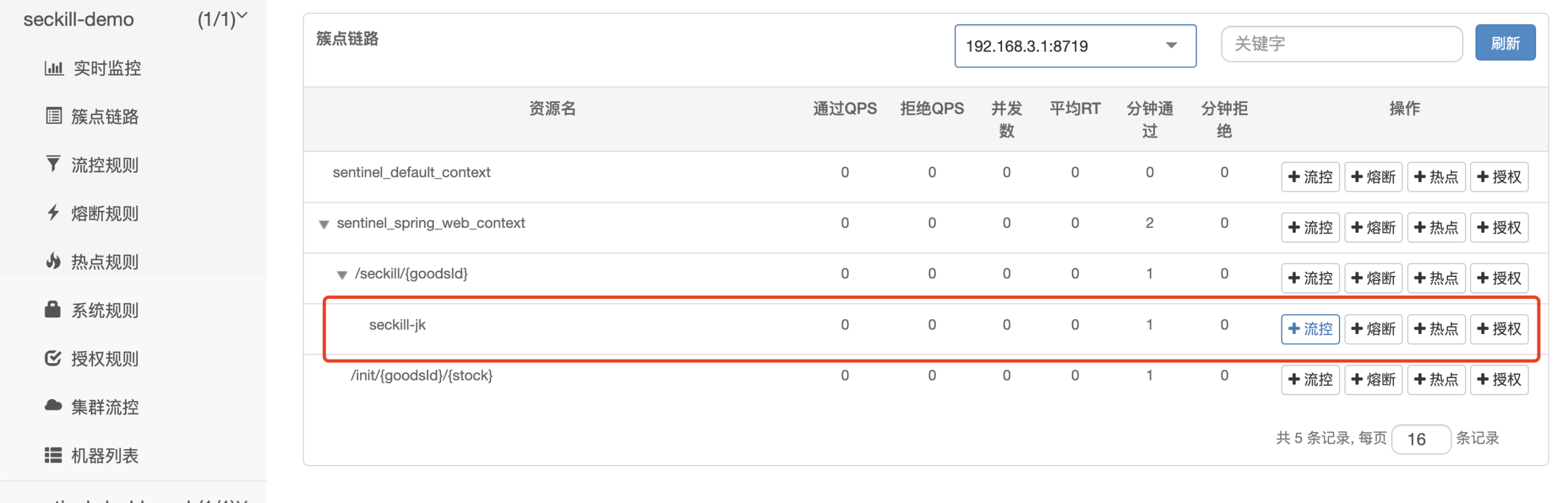
《从 0 到 1:我如何用 Redis + Lua + Kafka + Sentinel实现高并发秒杀防超卖》 本文介绍了一个基于SpringBoot3.2+Redis+Lua+Kafka+Sentinel的秒杀系统设计方案。针对高并发场景下的超卖、性能瓶颈和重复下单问题,采用Redis+Lua脚本实现原子性库... 国内服务器 5个月前470
如何利用大数据成为“增长黑客”? 增长黑客是近几年颇为流行的一个词汇,它是指利用数据、技术、产品等一系列手段为互联网产品获得快速用户增长的人。互联网的访问没有边界,用户量的增加对应成本的增加也几乎可以忽略不计,所以如何快速、大规模获取... 国内服务器 5个月前470
计算机毕业设计hadoop+spark+hive薪资预测 招聘岗位推荐系统 招聘可视化大屏 招聘爬虫 Python Tensorflow 机器学习 深度学习 本文介绍了一个基于Hadoop+Spark+Hive的薪资预测系统设计方案。系统整合大数据技术栈,通过Hadoop HDFS存储数据,Hive进行数据清洗,Spark加速特征工程和模型训练,最终实现高... 国内服务器 5个月前470
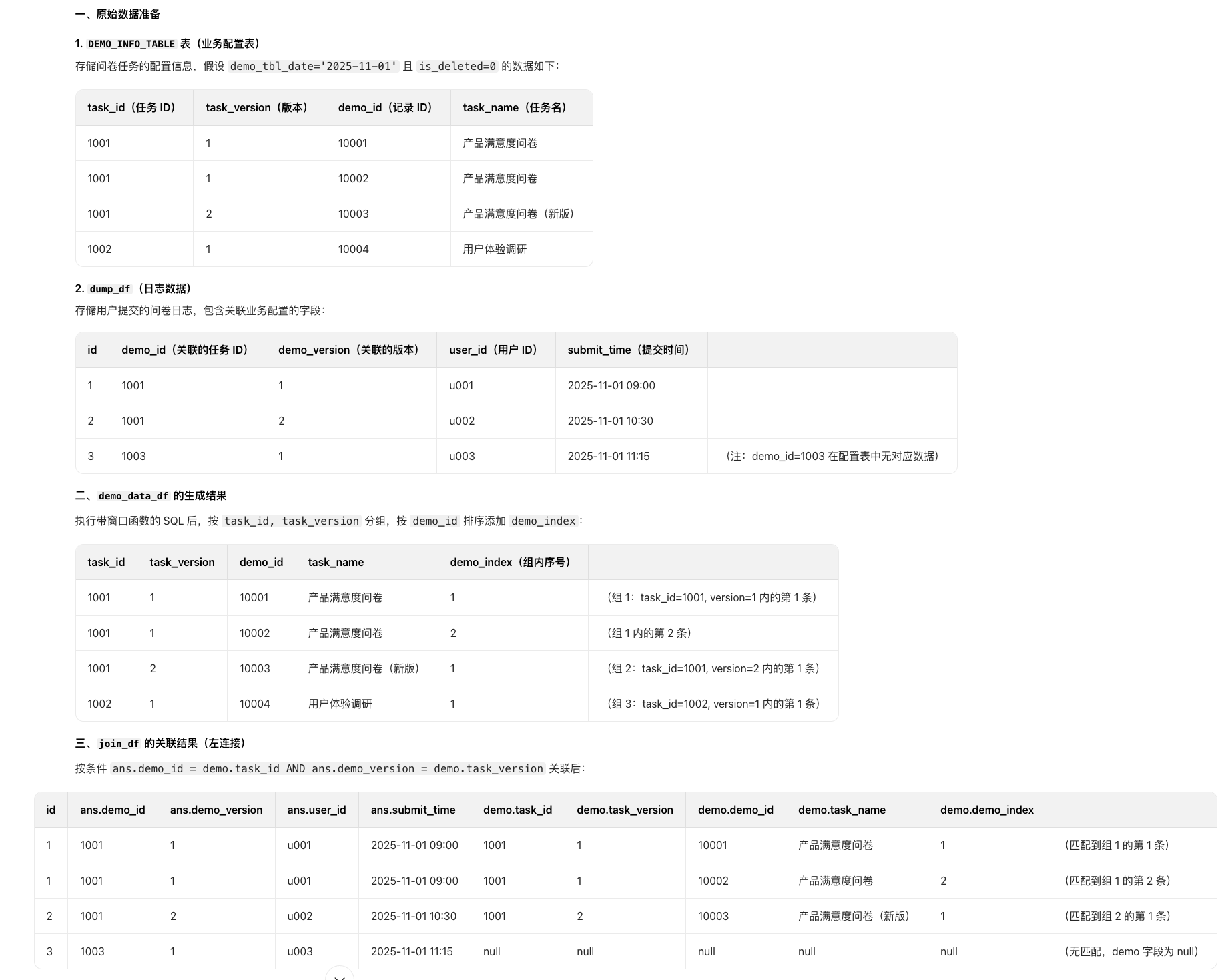
spark-SQL学习 假设 join_df 存储的是 “用户提交的问卷答案”,其中 answers 字段是一个嵌套列表(如 [{“question_id”: 1, “answer”: “A”}, {“question_id... 国内服务器 5个月前470
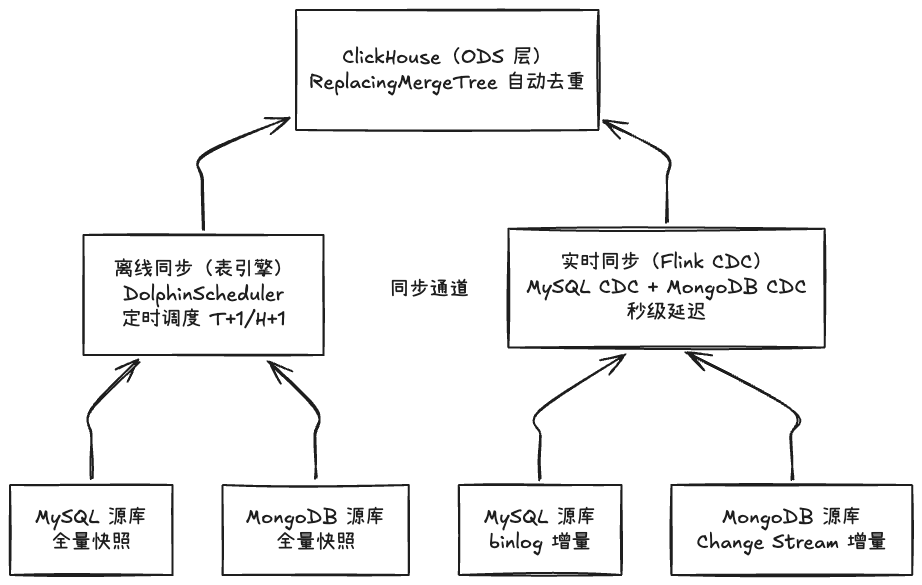
ClickHouse + Flink + DolphinScheduler:中小厂三件套搞定离线+实时数仓,告别 Hadoop 全家桶 本文介绍了一种轻量级离线+实时数仓解决方案,仅需ClickHouse、DolphinScheduler和Flink CDC三个组件。针对中小团队需求,该方案避免复杂Hadoop生态,实现高效低成本数仓... 国内服务器 2个月前460
大数据产品经理必备技能:数据治理与质量管控全解析 你有没有遇到过这样的场景?运营说“用户复购率算错了”,因为同一个用户有3个不同的ID;财务说“订单金额不对”,因为有100条负数订单;算法工程师说“推荐模型不准”,因为用户行为数据缺失了30%。这些问... 国内服务器 3个月前460
大数据深度学习|计算机毕设项目|计算机毕设答辩|Pyqt基于OpenCV的读码系统(OpenCV) 在当今数字化时代,读码系统在各个领域发挥着举足轻重的作用。尤其是在物流和生产等行业,读码系统已成为实现自动化、提高效率和准确性的关键技术之一。随着物流行业的快速发展,货物的高效追踪与管理成为核心需求... 国内服务器 4个月前460
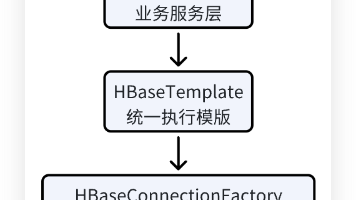
如何封装一个线程安全、可复用的 HBase 查询模板 本文探讨了如何封装一个线程安全、可复用的 HBase 查询模板。通过引入基于 AtomicReference 的连接懒加载机制和函数式接口封装查询执行逻辑,本文提供了一种高效的 HBase 查询解决方... 国内服务器 4个月前460