数睿通2.0升级:支持docker一键部署,升级flink版本,更新操作手册,优化数据开发、数据权限 更快把环境搭起来:系统包 + 组件包按需组合,一键跑通核心流程;更顺畅地接入业务系统:业务库新增 PostgreSQL / Kingbase 兼容支持;更放心地把作业跑起来:Flink 1.18/2... 国内服务器 1个月前210
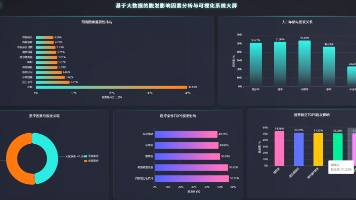
【数据分析】基于大数据的脱发影响因素分析与可视化系统 | 大数据可视化大屏 大数据实战项目 选题推荐 hadoop SPark 【数据分析】基于大数据的脱发影响因素分析与可视化系统 | 大数据可视化大屏 大数据实战项目 选题推荐 hadoop SPark 国内服务器 1个月前210
09-消息队列Kafka介绍:大数据世界的“物流枢纽” Kafka就像是大数据世界的物流枢纽解决了数据传输的瓶颈:高吞吐、低延迟的设计,让数据流动更加顺畅。提高了系统的可靠性:持久化、多副本的设计,确保数据不丢失。增强了系统的灵活性:解耦生产者和消费者,让... 国内服务器 1个月前200
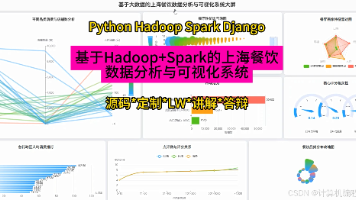
【计算机毕设选题】基于Hadoop+Spark上海餐饮数据分析系统源码 毕业设计 选题推荐 毕设选题 数据分析 机器学习 数据挖掘 本课题基于Hadoop与Spark构建上海餐饮数据分析系统,利用Python+Django进行后端开发。系统从宏观市场、质量口碑、消费行为、空间分布和客群画像五个维度,对海量餐饮数据进行处理与可视化... 国内服务器 1个月前200
大数据领域中Zookeeper与Kafka的协同工作模式 本文旨在全面解析Zookeeper与Kafka在大数据生态系统中的协同工作模式。Zookeeper作为分布式协调服务的核心功能Kafka作为分布式消息系统的架构特点两者之间的交互机制和依赖关系实际应用... 国内服务器 1个月前250
Spark大数据分析与实战笔记(第六章 Kafka分布式发布订阅消息系统-03) 通常情况下,我们使用Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时的进行业务计算,得出相应结果。也许生活中偶有黯淡无光的时刻,但别忘了还有未实现的梦想,努力朝着自己... 国内服务器 1个月前180
基于大数据爬虫数据挖掘技术+Python的线上招聘信息分析统计与可视化平台(源码+论文+PPT+部署文档教程等) 基于数据挖掘技术的线上招聘信息分析系统旨在通过应用先进的数据分析方法,为求职者和招聘者提供更加高效、精准的招聘服务。该系统具备强大的信息处理能力,能够从海量的招聘数据中提取有价值的信息,揭示市场趋势和... 国内服务器 1个月前220
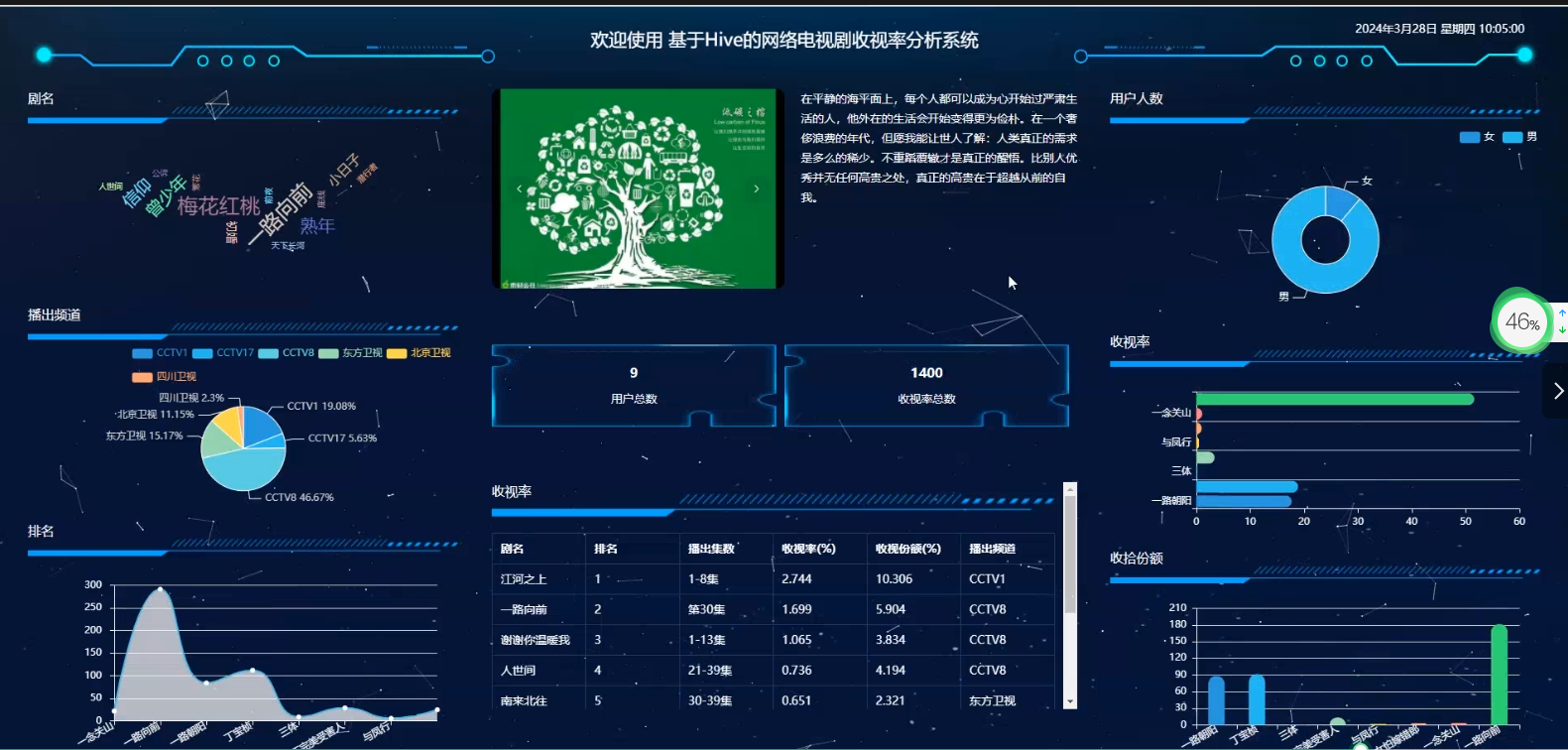
基于大数据爬虫+SpringBoot+Hive的网络电视剧收视率分析与可视化平台系统(源码+论文+PPT+部署文档教程等) 摘 要在当今数字化时代,网络电视剧作为一种新兴的娱乐形式,受到了广泛的关注和欢迎。随着网络电视剧市场的不断扩大和竞争的加剧,各大卫视平台纷纷推出了大量优质的网络电视剧,努力吸引观众和提升收视率。然而... 国内服务器 1个月前330
大数据领域的创新应用案例 当你每天刷手机产生的100条行为数据、超市收银机每秒打印的20张小票、医院CT机生成的3GB影像文件……这些看似无用的"数字碎片",正在通过大数据技术变成改变世界的"数字... 国内服务器 1个月前240