在 NVIDIA DGX Spark 上一键部署 NemoClaw:打造安全强大的沙盒化 AI Agent 摘要: NVIDIA推出NemoClaw解决方案,基于OpenShell沙盒技术,为AI Agent提供安全执行环境。本指南介绍如何在NVIDIA DGX Spark(搭载GB10 Grace Bla... 国内服务器 2个月前250
Hive学习记录第一章 Apache Hive是基于Hadoop的数据仓库系统,提供类SQL查询语言(HiveQL)处理PB级数据。其核心架构包含客户端接口、驱动服务、元数据存储和执行引擎四层,支持MapReduce、Tez... 国内服务器 2个月前250
大数据领域实时分析的算法优化策略 本文旨在系统性地介绍大数据实时分析领域的算法优化策略,帮助读者理解如何设计和实现高效的实时分析系统。我们将覆盖从基础概念到高级优化技术的完整知识体系,特别关注算法层面的性能优化方法。文章首先介绍实时分... 国内服务器 2个月前230
计算机毕业设计源码:锦江酒店大数据分析与个性化推荐系统 Django框架 Vue 可视化 Hadoop 爬虫 协同过滤推荐算法 民宿 客栈(建议收藏)✅ 本文介绍了一个基于Spark大数据框架的酒店数据分析与推荐系统。系统采用Python开发,结合Hadoop、Hive、Django和Vue等技术栈,通过Selenium爬虫采集锦江酒店数据,实现了数据... 国内服务器 2个月前290
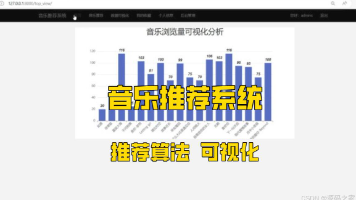
毕业设计源码:Python个性化音乐推荐系统 Django+协同过滤算法+Echarts可视化打造优质体验 人工智能 大数据(建议收藏)✅ 本文介绍了一个基于Python和Django框架开发的音乐推荐系统,采用协同过滤算法实现个性化推荐,并整合Echarts进行数据可视化。系统功能包括:首页音乐分类浏览与热门推荐、音乐播放与详情查看、用... 国内服务器 2个月前320
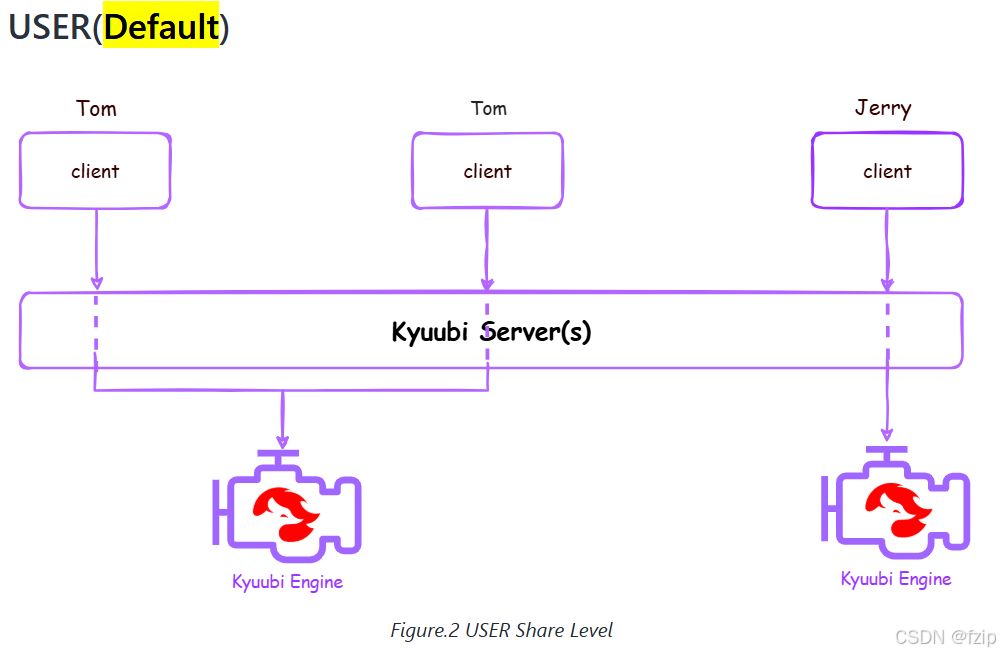
kyuubi+spark3.4.1单用户提交任务,yarn队列使用不满 Kyuubi 引擎共享级别是user级别,单个用户的任务跑在一个spark on yarn的集群上,队列大小为30TB,但是Spark executor内存8G+offheap8G、vcore4核,在... 国内服务器 2个月前260
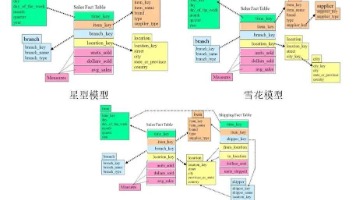
一文读懂系列:数据仓库为什么分层,分几层?数仓建模方法有哪些 数据仓库分层架构的核心价值在于提升数据处理效率和管理能力。主流分层模型包括基础三层(ODS-DWD-ADS)和标准四层(增加DWS层),选择取决于业务复杂度、团队规模和技术需求。维度建模是常用方法,通... 国内服务器 2个月前270
大数据领域分布式计算的分布式事务处理 随着大数据技术的快速发展,分布式系统已成为处理海量数据的标准架构。在这种环境下,如何保证跨多个节点的数据一致性成为关键挑战。本文旨在系统性地介绍分布式事务处理的核心概念、技术原理和实际应用,特别关注大... 国内服务器 2个月前420
毕业设计项目:【Spark+hadoop】基于Spark大数据小说数据分析可视化推荐系统(完整系统源码+数据库+开发笔记+详细部署教程+虚拟机分布式启动教程) 本项目开发了一个基于Spark和Hadoop的大数据小说推荐系统,采用协同过滤算法和Django框架实现个性化推荐。系统通过分析用户行为数据,提供精准小说推荐,提升用户体验和平台运营效率。技术栈包括M... 国内服务器 2个月前210
得物Java面试被问:Kafka的零拷贝技术和PageCache优化 本文深入解析Kafka高性能背后的关键技术:零拷贝和PageCache优化。零拷贝技术通过sendfile系统调用减少数据拷贝次数,将传统IO的4次拷贝简化为2次DMA拷贝,显著降低CPU使用率。Ka... 国内服务器 2个月前280