得物Java面试被问:Kafka的零拷贝技术和PageCache优化 本文深入解析Kafka高性能背后的关键技术:零拷贝和PageCache优化。零拷贝技术通过sendfile系统调用减少数据拷贝次数,将传统IO的4次拷贝简化为2次DMA拷贝,显著降低CPU使用率。Ka... 国内服务器 2个月前280
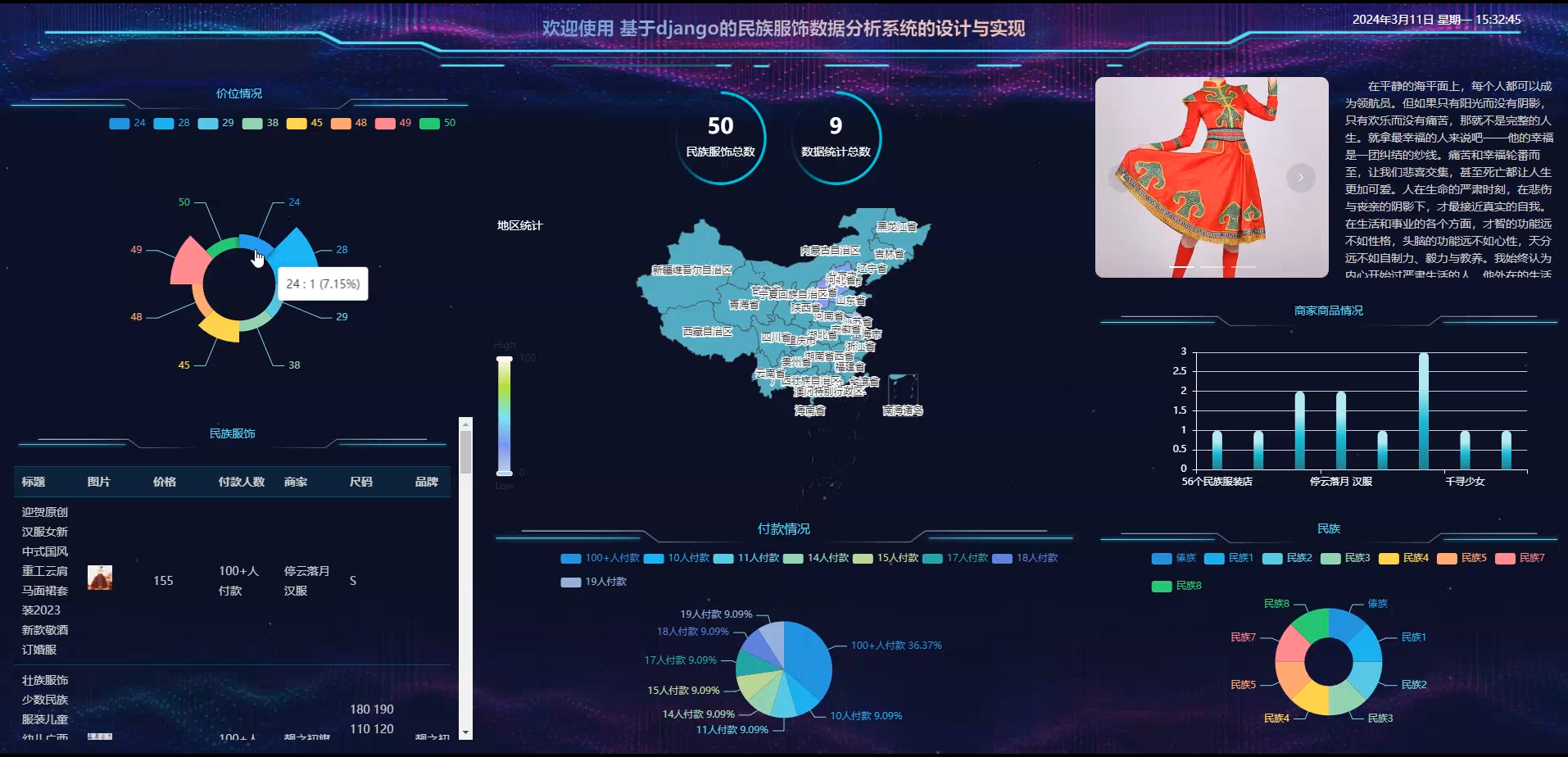
基于大数据爬+数据可视化的民族服饰数据分析系统设计和实现(源码+论文+部署讲解等) 随着网络科技的发展,利用大数据分析对民族服饰进行管理已势在必行;该平台将帮助企业更好地理解服饰市场的趋势,优化服装款式,提高服装的质量。本文讲述了基于python语言开发,后台数据库选择MySQL进行... 国内服务器 2个月前530
在DGX-Spark上多模态模型gemma-4-31B-it vLLM部署 显存优化fp8量化 + 70% 显存限制 + 分块预填充,适合大模型部署性能优化:前缀缓存 + SafeTensors 格式,提升重复查询和加载速度功能特性:支持工具调用(Tool Calling)和... 国内服务器 2个月前270
基于大数据的家政服务平台系统–毕设附源码70924 系统分为用户端、员工端和管理员端。用户端提供服务预约、评价反馈等功能,满足用户便捷获取家政服务的需求;员工端支持添加家政服务、预约记录审核、在线考试等操作,助力家政人员提升专业能力与工作效率;管理员端... 国内服务器 2个月前840
Java-208 RabbitMQ Topic 主题交换器详解:routingKey/bindingKey 通配符与 Java 示例 消息携带 routingKey(dotted-word,长度≤255字节),队列用 bindingKey 绑定到交换器;* 匹配“恰好1个词”,# 匹配“0到多个词”,通配符必须作为独立词出现。结合日... 国内服务器 2个月前250
Spring Boot 4.0 整合 Kafka 企业级应用指南 生产者配置设置acks=all确保消息可靠性启用幂等性合理设置重试次数和超时时间使用压缩减少网络传输消费者配置禁用自动提交,使用手动提交合理设置避免内存溢出配置合适的心跳和会话超时时间使用消费者组实现... 国内服务器 2个月前250
Kafka 消息持久化深度解析:从 PageCache 到磁盘的奥秘 消息持久化是指将消息数据保存到非易失性存储介质(如磁盘)中,以确保在系统故障、重启等情况下数据不会丢失。Kafka 的设计哲学之一是"数据不丢失",它将所有消息持久化到磁盘,并提供... 国内服务器 2个月前300
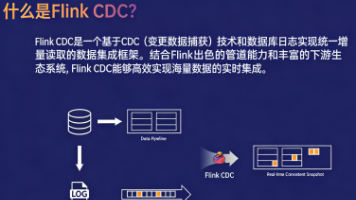
保姆级教程:Apache Flink CDC(standalone 模式)部署 MySQL CDC、PostgreSQL CDC 及使用方法 Apache Flink CDC 是一个数据集成框架,它基于数据库日志的 CDC(变更数据捕获)技术实现了统一的增量和全量数据读取。结合 Flink 出色的管道能力和丰富的上下游生态系统,Flink ... 国内服务器 2个月前220
基于Spark的毕业设计论文:从实战项目选题到可运行系统的完整实现 面对大数据处理框架,常见的选择有Hadoop MapReduce、Spark和Flink。对比Hadoop MapReduce:Spark基于内存计算,速度上有数量级的优势,其API(RDD、Data... 国内服务器 2个月前260
Flink监控体系实战:从零构建企业级运维平台 Apache Flink作为流处理领域的领军框架,其强大的实时数据处理能力已被广泛应用于各类企业级场景。然而,随着集群规模扩大和作业复杂度提升,构建一套完善的监控体系成为保障系统稳定运行的关键。本文将... 国内服务器 2个月前210