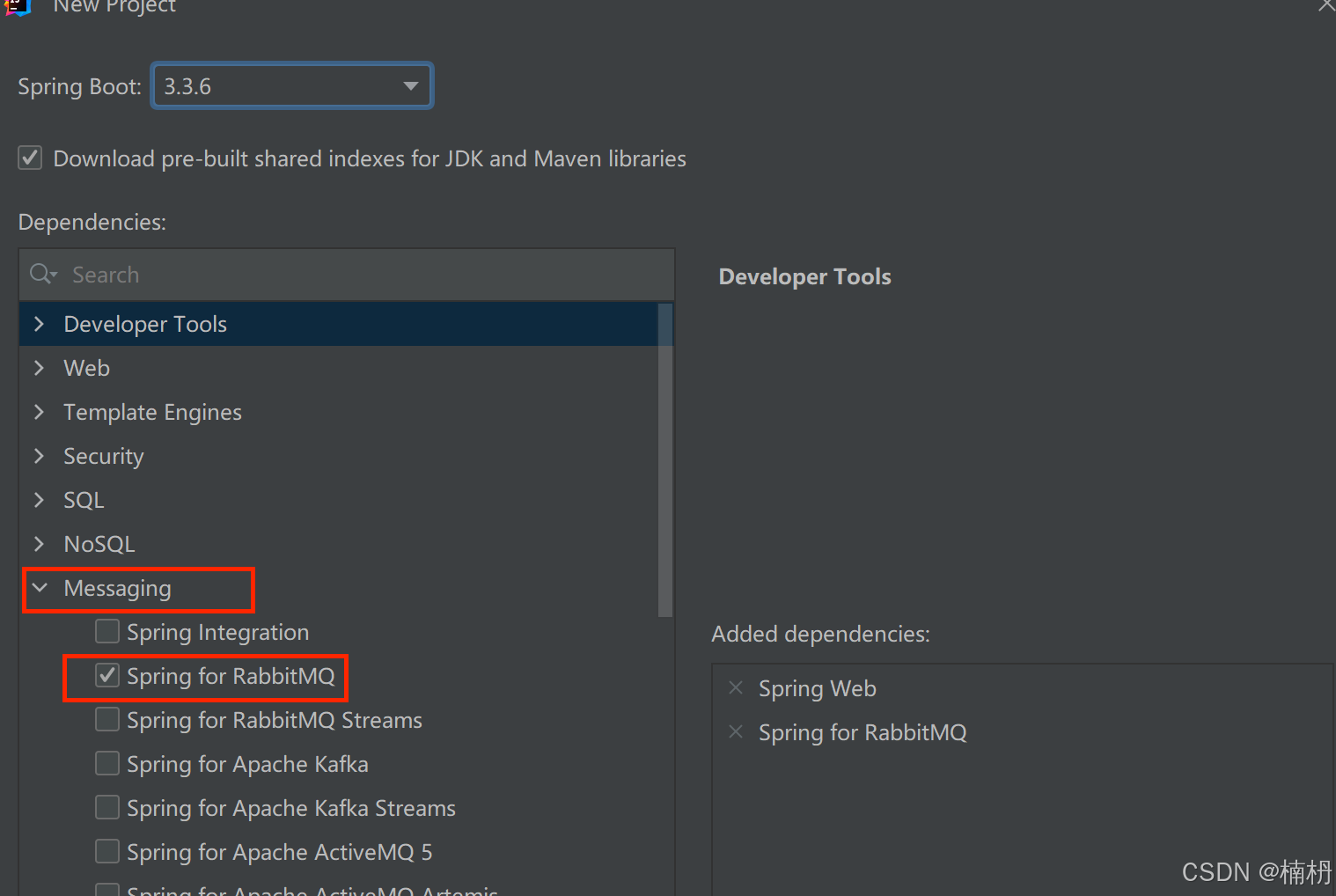
Spring Boot 中 RabbitMQ 的使用 在本篇文章中,我们就来在Spring Boot 中实现常见的工作模式,进而学习在 Spring Boot 中如何使用 RabbitMQ 国内服务器 4个月前400
python新浪微博评论分析系统 大数据-爬虫 新浪微博作为中国最大的社交媒体平台之一,每天产生海量的用户评论数据。这些数据蕴含丰富的用户情感、舆论倾向和市场反馈信息。通过Python构建的微博评论分析系统,结合大数据技术与网络爬虫,能够高效采集... 国内服务器 4个月前400
DolphinScheduler启动flink任务, 用Flink消费Kafka数据(linux) 1、修改kafka配置:找到kafka安装包下的config文件夹,修改config下的server.properties文件,修改listeners是为了外面的主机能够访问到虚拟机的kafka,还有... 国内服务器 4个月前400
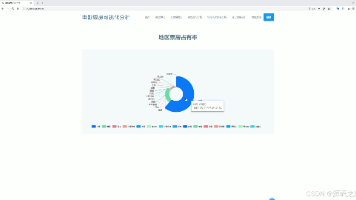
电影票房数据采集分析可视化系统 | Python Flask Echarts requests爬虫 大数据 人工智能 deepseek 毕业设计源码 本文介绍了一个基于Python的电影票房数据采集分析可视化系统。系统采用Flask框架搭建后端,MySQL存储数据,通过requests库爬取艺恩电影票房网数据,并利用Echarts实现可视化展示。主... 国内服务器 4个月前400
RabbitMQ快速上手与核心概念详解 本文介绍了消息队列(MQ)的概念、作用和主流产品对比,重点讲解了RabbitMQ的安装配置与核心概念。MQ作为异步通信中间件,具有解耦、异步和削峰填谷三大优势。文章详细说明了RabbitMQ的安装步骤... 国内服务器 4个月前400
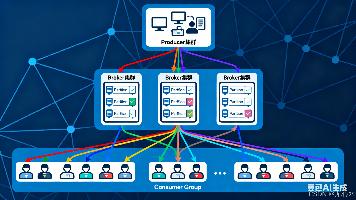
【分布式利器:Kafka】Kafka基本原理详解:架构、流转机制与高吞吐核心(附实战配置) Kafka是一个分布式流处理平台,以高吞吐、高可靠和高扩展性著称,广泛应用于日志收集、实时分析和数据同步场景。其核心架构包括生产者、消费者、Broker节点、Topic和Partition,通过分区并... 国内服务器 4个月前400
中小型企业大数据平台全栈搭建:Hive+HDFS+YARN+Hue+ZooKeeper+MySQL+Sqoop+Azkaban 保姆级配置指南 对于中小企业,构建一套完整的本地化大数据平台需兼顾成本、易用性和扩展性。本文基于生产环境实践,详细讲解以下组件的安装、配置与联动;提供全组件官方下载地址和 配置模板,助您快速搭建企业级数据平台 国内服务器 4个月前400
Java 大视界 — Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制(273) 本文系统阐述 Java 大数据技术在智能安防视频监控中的应用,涵盖分布式架构设计、AI 算法实现、性能优化及隐私保护方案,结合真实案例提供可落地的技术指南。 国内服务器 4个月前400
深度解析Sarama:如何构建高性能Go语言Kafka客户端完整指南 在现代微服务架构中,消息队列已成为系统解耦和数据流转的核心组件。然而,当开发者面对**高吞吐量**、**低延迟**和**数据一致性**的严苛要求时,传统的Kafka客户端往往难以满足复杂的业务场景。特... 国内服务器 4个月前400