Java 大视界 — Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制(273) 本文系统阐述 Java 大数据技术在智能安防视频监控中的应用,涵盖分布式架构设计、AI 算法实现、性能优化及隐私保护方案,结合真实案例提供可落地的技术指南。 国内服务器 4个月前400
计算机毕设推荐:基于大数据的各省碳排放数据分析与可视化系统实战 《基于大数据的各省碳排放数据分析与可视化系统》是一套专为计算机专业设计的毕业项目,采用Python+Spark技术栈实现。系统通过大数据技术处理海量碳排放数据,提供时间趋势、区域对比和排放结构等多维度... 国内服务器 4个月前400
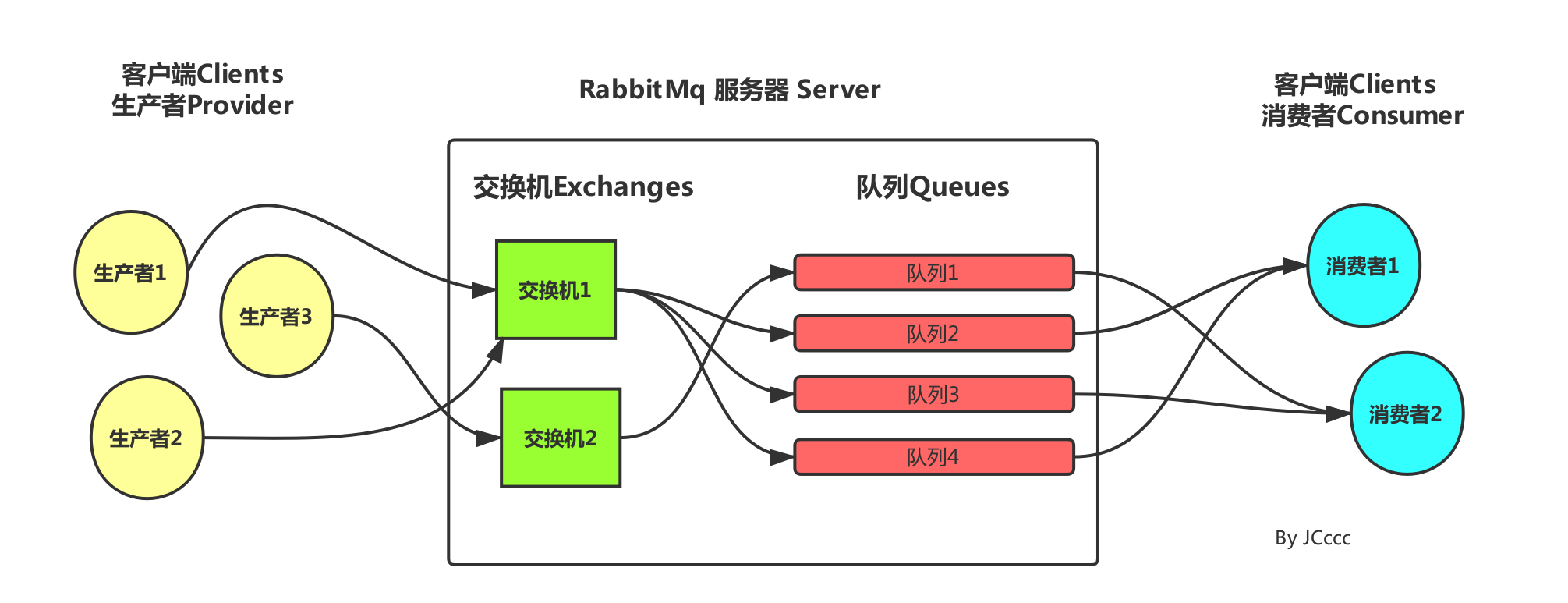
RabbitMQ之交换机 在讲交换机之前我们需要了解一些概念,在RabbitMQ工作流程有一项叫Exchange(交换机:消息的分发中心****),它的作用是将生产者发送的消息转发到具体的队列,队列再将消息以推送或者拉取方式给... 国内服务器 4个月前400
Windows/Linux 环境下 Kafka 集群搭建指南(附避坑手册) 本文详细介绍了在Windows和Linux环境下搭建Kafka集群的完整流程。主要内容包括:Kafka集群的核心依赖与架构解析,JDK环境配置和安装包获取等通用准备工作,以及分别针对Linux和Win... 国内服务器 4个月前400
Pyspark学习二:快速入门基本数据结构 实际工作中其实不需要自己安装和配置,更重要的是会用。所以就不研究怎么安装配置了。前面介绍过:简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数... 国内服务器 4个月前400
大数据视角下的时序数据库选型:Apache IoTDB 核心竞争力拆解 随着5G、物联网与工业互联网的深度融合,时序数据正以爆炸式速度增长——工业传感器的高频采集、智能电网的实时监测、车联网的动态反馈,每天都在产生PB级时序数据。据统计,2025年国内企业时序数据产生量同... 国内服务器 5个月前400
大数据领域数据架构的缓存策略优化 本文旨在为大数据工程师、架构师和开发人员提供全面的缓存策略优化指南。我们将重点讨论大数据环境下的缓存技术,包括但不限于Redis、Memcached等流行缓存系统的优化策略,以及如何将这些技术与Had... 国内服务器 5个月前400
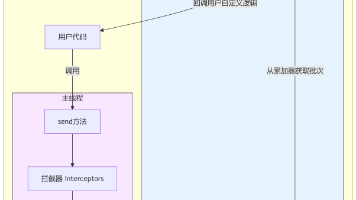
【深度解析】Kafka生产者核心原理:从异步发送到数据可靠性保证 摘要: 本文深入解析Kafka生产者的核心原理,涵盖异步发送、回调机制、分区策略及数据可靠性保证。通过架构图展示生产者内部的双线程设计(主线程与Sender线程),解释高吞吐量的实现关键——批处理与缓... 国内服务器 5个月前400