【大数据】车辆二氧化碳排放量可视化分析系统 Hadoop+Spark技术 计算机毕业设计项目 Anaconda+Hadoop+Spark环境配置 附源码+文档+讲解 基于大数据的车辆二氧化碳排放量可视化分析系统是一个面向车辆碳排放数据管理与分析的综合性平台,该系统采用Hadoop与Spark作为大数据处理框架,通过HDFS实现海量数据的分布式存储,利用Spark ... 国内服务器 2个月前260
电影推荐系统 | Python Django框架 双数据库 协同过滤 requests bootstrap3 大数据 毕业设计源码 文章摘要: 本项目开发了一个基于Python+Django的电影推荐系统,采用协同过滤算法实现个性化推荐。系统包含数据采集(爬取豆瓣3000条电影数据)、电影展示(多维度分类与搜索)、用户交互(登录... 国内服务器 2个月前390
当Hadoop遇见实时推荐:分布式系统在音乐场景中的架构演进 本文探讨了音乐推荐系统从批处理到实时计算的架构演进,重点分析了Hadoop在音乐推荐场景中的应用与优化。通过对比不同技术栈(如Flink、Spark Streaming)的性能特点,详细解析了实时推荐... 国内服务器 2个月前250
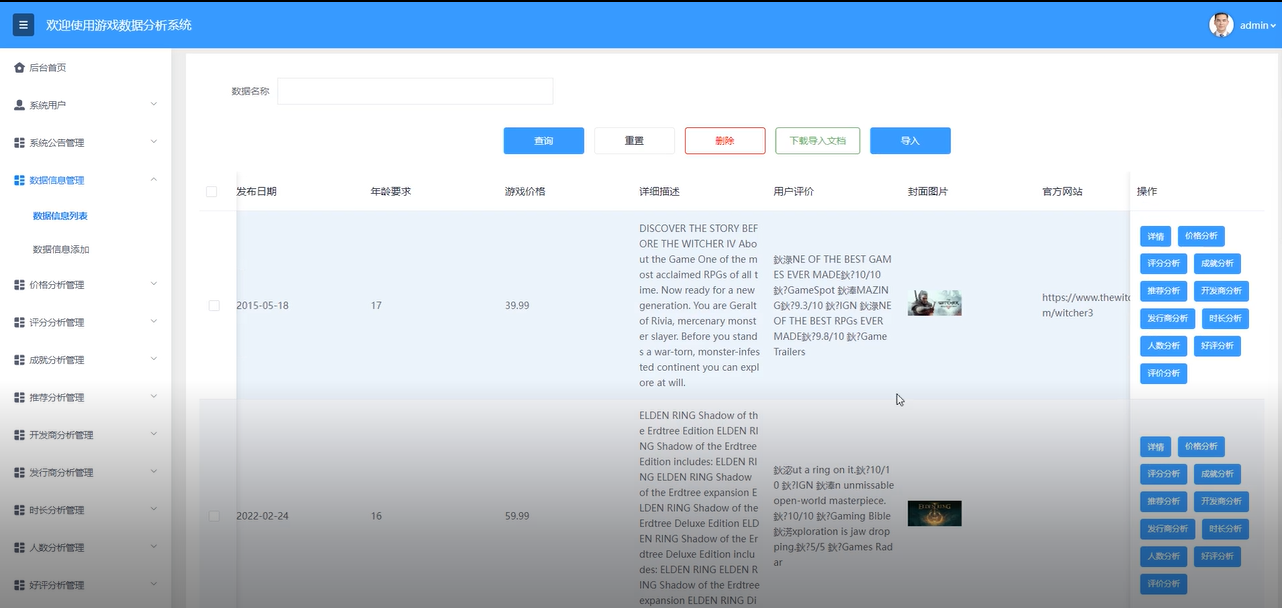
基于Hadoop的游戏数据分析系统—免费毕设源码分享63632 随着大数据技术的迅速发展,游戏产业迎来了前所未有的数据爆炸,如何高效地分析和利用这些数据成为关键问题。本文提出了一种基于Hadoop的游戏数据分析系统,利用HDFS进行海量数据的分布式存储,结合Had... 国内服务器 2个月前580
基于大数据的人力资源招聘数据分析与可视化 本文基于Java开发环境,采用Spring Boot框架构建了一个大数据招聘分析平台。系统整合了爬虫技术采集多源招聘数据,利用Hadoop分布式存储处理海量信息,并通过Python可视化工具进行交互展... 国内服务器 2个月前240
气象数据分析与可视化系统:基于Spark的大数据处理方案(中科院计算机研究生) 本文介绍了一个基于Spark和Python的气象数据分析项目,专注于高效处理大规模气象数据并生成可视化图表。项目采用双版本实现(Spark+Pandas),严格遵循气象观测标准计算日平均气温,处理57... 国内服务器 2个月前320
大数据领域数据架构的农业数据挖掘与应用 农业作为人类最古老的生产活动之一,正经历着由传统向数字化、智能化转型的关键时期。本文旨在探讨如何利用大数据技术解决农业生产中的关键问题,包括作物产量预测、病虫害预警、精准灌溉和资源优化等。研究范围涵盖... 国内服务器 2个月前340
Spark-TTS语音合成:新手10分钟从零到精通实战指南 作为一款强大的开源语音合成工具,Spark-TTS语音合成系统在实际使用中可能会遇到各种技术障碍。本文专为新手用户设计,通过"问题发现→快速解决→深度优化"的三段式结构,帮助你快速... 国内服务器 2个月前310
分布式锁超时处理全攻略(含Redis/ZooKeeper对比实践) 掌握分布式锁的超时处理关键方法,避免死锁与资源争用。对比Redis与ZooKeeper实现方案,涵盖适用场景、自动续期与容错机制,提升系统可靠性,值得收藏。 国内服务器 2个月前350
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 routingKey 与 bindingKey 的精确匹配机制,并用日志分流场景给出可直接复用的 Java(amqp-client)示例:生产者向 direct_logs 按 severity(inf... 国内服务器 2个月前280