大数据项目(一):Hadoop 云网盘管理系统开发实践 在日常工作和学习中,我们经常需要管理大量的文档资料。传统的本地存储方式存在诸多不便:文件分散难以统一管理、跨设备访问困难、数据安全性无法保障等。因此,我开发了 **NetWorkBase** —— 一... 国内服务器 3个月前330
解析ESP-SparkBot开源大模型AI桌面机器人的ESP32-S3核心方案 ESP-SparkBot是一款基于ESP32-S3微控制器的开源AI桌面机器人,采用边缘-云端协同架构实现多模态交互。核心硬件包括双核处理器、Wi-Fi/蓝牙模块及丰富外设接口,支持语音识别、图像处理... 国内服务器 2个月前350
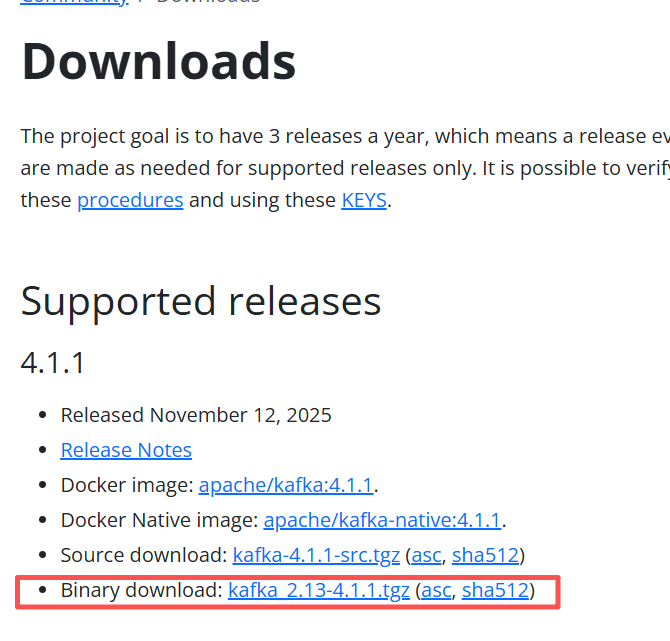
Kafka部署指南:单机开发模式与集群生产模式( 4.1.1 版本) 单机开发模式:适合功能验证和开发测试,配置简单,资源需求低集群生产模式:提供高可用性和容错能力,适合线上业务使用Kafka 4.1.1 完全移除对 ZooKeeper 的依赖,简化了架构部署,同时保持... 国内服务器 3个月前310
DolphinScheduler启动flink任务, 用Flink消费Kafka数据(linux) 1、修改kafka配置:找到kafka安装包下的config文件夹,修改config下的server.properties文件,修改listeners是为了外面的主机能够访问到虚拟机的kafka,还有... 国内服务器 2个月前310
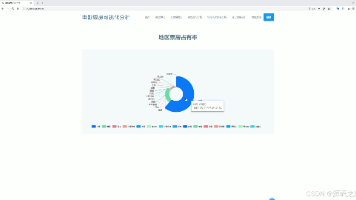
电影票房数据采集分析可视化系统 | Python Flask Echarts requests爬虫 大数据 人工智能 deepseek 毕业设计源码 本文介绍了一个基于Python的电影票房数据采集分析可视化系统。系统采用Flask框架搭建后端,MySQL存储数据,通过requests库爬取艺恩电影票房网数据,并利用Echarts实现可视化展示。主... 国内服务器 3个月前290
仅限今日公开:Kafka Streams复杂事件过滤的内部实现原理 深入解析Kafka Streams数据过滤的内部实现原理,揭示复杂事件处理的高效机制。适用于实时风控、日志筛选等场景,基于DSL与处理器API灵活构建过滤逻辑,具备低延迟、高吞吐优势。原理剖析+实战要... 国内服务器 2个月前260
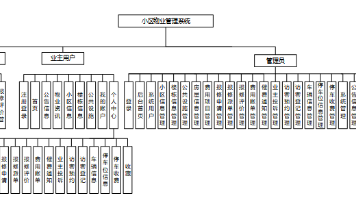
【Java小区物业管理系统】(免费领源码+演示录像)|可做计算机毕设Java、Python、PHP、小程序APP、C#、爬虫大数据、单片机、文案 该系统采用了Spring Boot作为核心框架,结合了MySQL数据库用于数据存储,以及Thymeleaf模板引擎实现动态网页展示。设计上,系统集成了用户注册登录、公告信息发布、物业费用管理、报修申请... 国内服务器 3个月前480
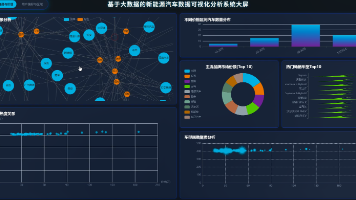
【数据分析】基于大数据的新能源汽车数据可视化分析系统 | 大数据毕设选题 数据可视化 实战项目 hadoop SPark 摘要:本文介绍了一套基于大数据技术的新能源汽车数据可视化分析系统。该系统采用Hadoop+Spark架构,支持Python/Java双后端,通过Spark SQL进行数据清洗和聚合分析,结果存储于My... 国内服务器 2个月前380
大数据深度学习|计算机毕设项目|计算机毕设答辩|PyQt井下煤矿低光照图像增强与人员检测系统开发 通过为其绑定相应的槽函数(在 Python 中通常使用 pyqtSignal 和 slot 机制来实现信号与槽的关联),当用户点击按钮时,对应的操作函数被触发执行,从而实现对应的功能逻辑,比如点击 ... 国内服务器 3个月前350
大数据领域中RabbitMQ的高效配置指南 在大数据场景中(如实时日志采集、用户行为分析、订单流处理),系统每天需要处理数千万甚至数亿条消息。普通消息队列可能在高并发下出现"堵车"(延迟飙升)、“丢件”(消息丢失)或&quo... 国内服务器 2个月前320