《数据治理实战指南》—【第三部分 实施篇】第7章 数据仓库及数据模型管理 数据仓库是为更好地分析和处理数据,面向主题来组织数据的存储系统。数据模型是定义数据结构、关系与规则的蓝图,是数据仓库的架构基础。数据模型决定了数据的组织逻辑与存储规范,数据仓库则是该模型的具体物理实现... 国内服务器 3个月前280
hive知识点 并行执行:默认情况下,Hive一次只会执行一个阶段,通过设置参数hive.exec.parallel值为true,就可以开启并发执行,将MapReduce阶段、抽样阶段、合并阶段、limit阶段,这些... 国内服务器 3个月前250
从零开始:手把手教你构建Kafka Docker镜像全流程 你是否曾经为配置Kafka环境而头疼不已?复杂的依赖关系、版本兼容性问题常常让人望而却步。今天,我们将一起探索如何通过Docker技术,轻松构建一个可移植、易部署的Kafka运行环境。## 为什么选择... 国内服务器 3个月前240
【C#图书借阅系统】(免费领源码+演示录像)|可做计算机毕设Java、Python、PHP、小程序APP、C#、爬虫大数据、单片机、文案 图书借阅系统主要包括了前端net技术,后端vue框架技术的开发,数据库的建立和后台管理员的管理,并且采用 net语言进行开发,使用SQLServer数据库存储相关的数据。从而实现了图书借阅管理的相关功... 国内服务器 3个月前280
Hadoop 学习心得与实践沉淀 随着学习深入,我逐渐明白:Hadoop 的核心价值不在于 “新潮”,而在于其解决海量数据存储与计算痛点的底层逻辑 ——“化整为零” 的分布式思维,既是它立足行业十余年的根本,也是我后续学习中最受启发的... 国内服务器 3个月前260
小红书面试真题-Kafka持久化机制与ISR原理 本文深入解析Kafka持久化机制与ISR原理。Kafka采用顺序写磁盘和分段存储设计,通过零拷贝技术实现高吞吐,完美适配小红书海量日志场景。ISR机制通过同步副本集合保证消息可靠性,包含Leader和... 国内服务器 3个月前520
消息队列选型:Kafka vs RabbitMQ vs Redis 深度对比 消息队列作为分布式系统架构的核心组件,在解耦服务、削峰填谷、异步处理等场景中发挥着不可替代的作用。本文深入对比分析 Kafka、RabbitMQ、Redis 三种主流消息队列方案,从架构设计、消息模型... 国内服务器 3个月前260
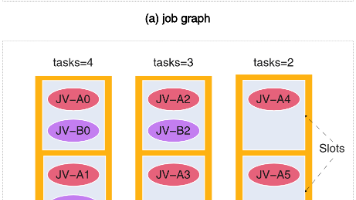
Flink Balanced Tasks Scheduling:并行度不一致时,怎么把 TaskManager “压得更均匀” Flink的Delegation Token(DT)机制是一种短/中期认证令牌,解决了三大问题:避免分发长期凭证、减轻KDC压力、明确权限边界。其架构由JobManager负责生成和更新Token,T... 国内服务器 3个月前280
【数据库】时序数据库选型指南:从大数据视角看 Apache IoTDB 的跨“端 – 边-云”架构优势 摘要 在物联网时代,时序数据管理面临写入性能、存储效率和查询分析等挑战。Apache IoTDB作为专为工业物联网设计的时序数据库,通过独特的树表孪生模型实现高效数据管理:树模型贴合设备层级关系,优化... 国内服务器 3个月前290