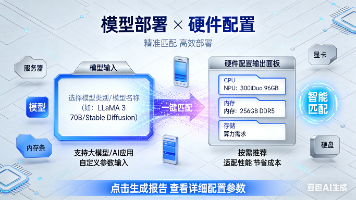
腾讯云 AI 视觉计费系统如何利用 Flink 状态管理实现精准去重 本文详细解析了腾讯云AI视觉计费系统如何利用Flink状态管理实现精准去重,涵盖RocksDB状态后端、TTL机制、复合Key策略等核心技术。通过优化Checkpoint配置和两阶段提交,系统每天处理... 国内服务器 3个月前320
两级液氧甲烷不锈钢火箭健康管理系统深度解读与总体方案设计 火箭健康管理系统通过"四层三环"架构实现全生命周期预测性维护,将传统定期检修转变为基于状态的精准维护。系统整合传感器网络、数字孪生和AI分析,建立"... 国内服务器 3个月前260
两级液氧甲烷不锈钢火箭飞行控制系统深度解读与总体方案设计 本文提出了一种新一代智能飞行控制系统,采用"云-边-端"三级协同架构,实现了从传统程序制导向自适应智能制导的跨越。系统通过在线轨迹优化、自适应控制和智能故障处置三位... 国内服务器 3个月前260
ClickHouse OLAP 数据仓库在互联网大规模分析场景下性能优化与查询加速实践经验分享 通过 ClickHouse OLAP 系统优化实践,可以在大规模互联网业务中实现:PB 级数据实时分析毫秒级查询响应热点数据自动缓存加速副本与多活机制保证高可用批量写入与分区策略提高吞吐全链路监控与资... 国内服务器 3个月前280
OpenClaw(养龙虾) +关于Hadoop hive的Skills(CLoudera CDH、CDP) 摘要:OpenClaw生态未内置Hadoop/Hive专用技能,因其企业级特性难以通用化。建议通过组合基础技能实现操作:1)使用tmux/session-logs管理长时任务;2)通过shell/ex... 国内服务器 3个月前340
Spark-Submit参数介绍及任务资源使用测试 yarn-client模式中,通过指定“--num-executors”参数则默认为Spark任务启动2个Executor;提交任务后,可以通过WebUI查看当前Application使用资源情况:A... 国内服务器 3个月前270
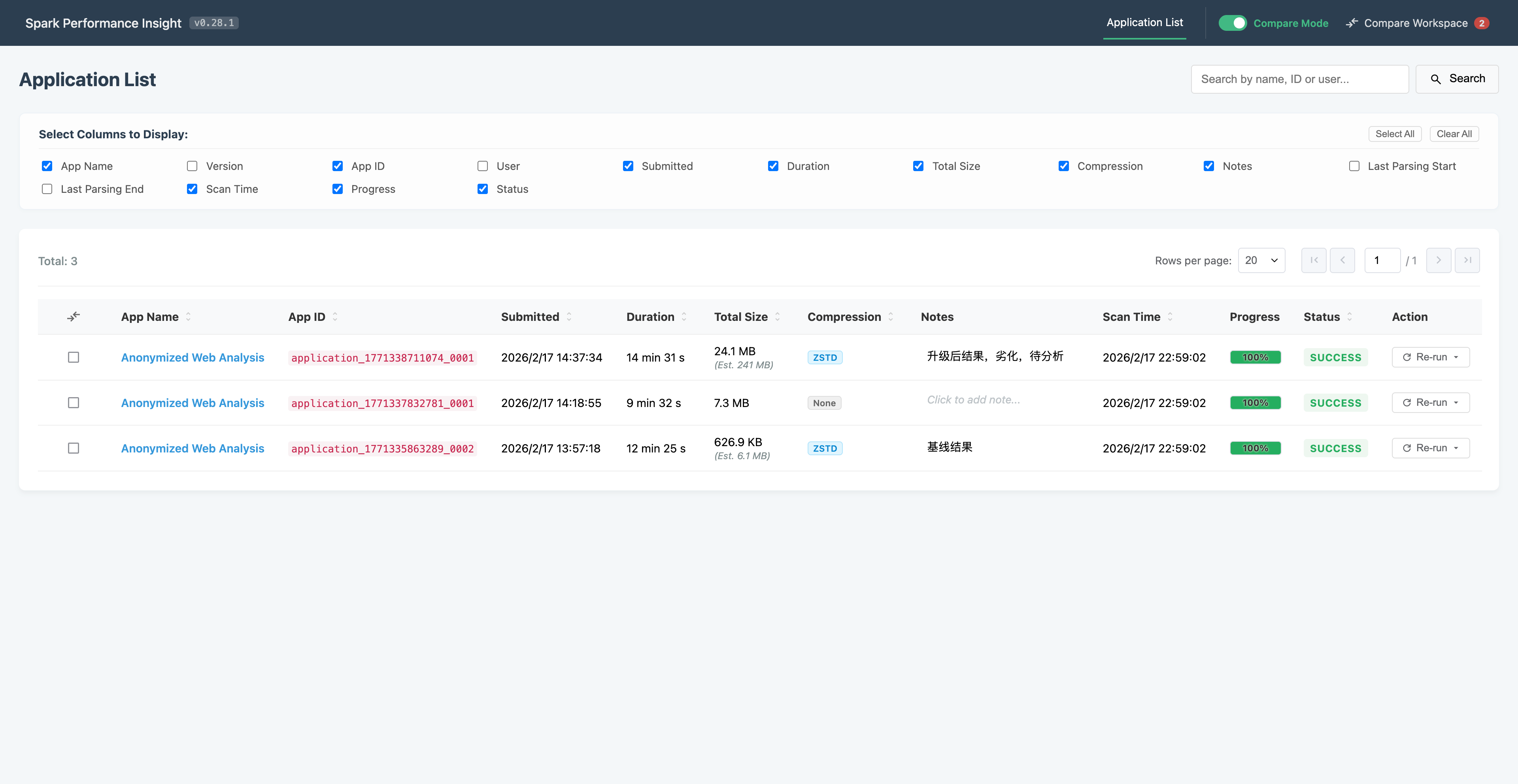
从“吐槽”到“交付”——我是如何协同 AI 撸出一个 Spark 性能分析工具的(上) 本文记录了一位后端开发者利用AI协作在3周内完成Spark性能分析工具开发的真实经历。通过"吐槽驱动开发"模式,作者实现了三大突破:跨越10年前端技术断层、24倍性... 国内服务器 3个月前280
【Filebeat+Kafka+ELK企业级日志系统实战部署:详解Kafka、Filebeat核心知识与ELK集成场景,Kafka集群部署、组件配置与验证,Filebeat部署及Kibana可视化】 本文介绍在ELK系统中加入Kafka和Filebeat的部署方案。Kafka作为高吞吐量消息队列,实现日志缓冲和削峰填谷;Filebeat作为轻量级日志采集工具,负责实时采集并转发日志至Kafka。文... 国内服务器 3个月前270
大数据领域的分布式文件系统 在大数据时代,数据量呈现爆炸式增长,传统的文件系统难以满足大规模数据存储和高效访问的需求。分布式文件系统应运而生,它将数据分散存储在多个节点上,通过网络进行统一管理和访问,提高了数据的可靠性、可扩展性... 国内服务器 3个月前260