RabbitMQ 中 Ready 和 Unacked 到底是什么意思?如何用它们判断系统是否健康 摘要:RabbitMQ中的Ready和Unacked指标是判断系统健康的关键指标。Ready表示队列中待消费的消息数量,其持续增长反映消费能力不足;Unacked表示已投递但未确认的消息数量,高值可能... 国内服务器 4个月前320
Hive排序与分发深度解析:ORDER BY、SORT BY、DISTRIBUTE BY、CLUSTER BY 区别详解 全局排序ORDER BY,一个Reducer拖到底局部排序SORT BY,每个文件自己比数据分发DISTRIBUTE BY,相同key到一起分发排序CLUSTER BY,两者结合限制你。 国内服务器 4个月前320
大数据生命周期全流程解析:采集、存储、分析、归档 本文旨在系统性地介绍大数据生命周期的完整流程,涵盖从数据产生到最终归档的各个环节。我们将重点探讨每个阶段的核心技术、挑战和最佳实践,为读者提供一个全面的大数据处理视角。文章将按照大数据生命周期的自然顺... 国内服务器 4个月前320
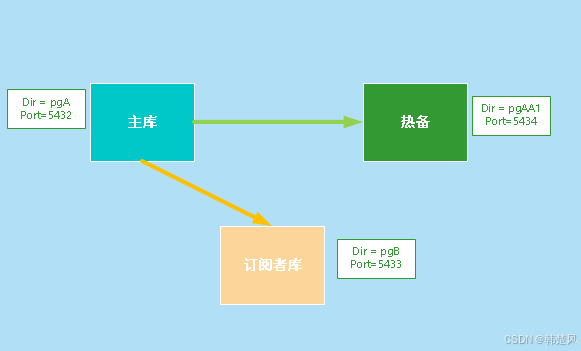
【PostgreSQL使用】最新功能逻辑复制槽的failover,大数据下高可用再添利器 使用数据库除了存取数据快捷以外,还有一个非常重要的目的,就是它有一整套的机制来保障数据访问的高可用,持续性。当然逻辑复制也不例外,当我们正在订阅的主库故障发生主备切换时,仍然希望数据库对象的变更订阅不... 国内服务器 4个月前320
【Hadoop+Spark+python毕设】气象地质灾害数据可视化分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 【Hadoop+Spark+python毕设】气象地质灾害数据可视化分析系统、计算机毕业设计、包括数据爬取、数据分析、数据可视化、实战教学 国内服务器 4个月前320
Spark持久化机制详解:从persist()到存储级别选择 对比维度核心优势极致性能稳定可靠适用数据量小于可用内存可大于可用内存容错能力依赖血统重算磁盘备份,无需重算GC压力较大较小适用场景小数据集、迭代算法大数据集、ETL作业选择口诀数据量小内存足,MEMO... 国内服务器 4个月前320
Flink与Hive集成:批流一体的大数据仓库方案 传统批流分离的痛点与批流一体的价值Flink与Hive集成的核心技术原理(元数据、存储、计算层协同)从环境搭建到代码实战的全流程操作指南电商、金融等典型行业的落地场景本文将按照“故事引入→核心概念→原... 国内服务器 4个月前320
大数据数据服务中的连接池优化 本文旨在帮助开发者和架构师理解大数据服务中连接池的重要性,并提供实用的优化策略。我们将覆盖从基础概念到高级优化的完整知识体系,重点讨论HikariCP、Druid等主流连接池在大数据场景下的应用。核心... 国内服务器 2个月前310
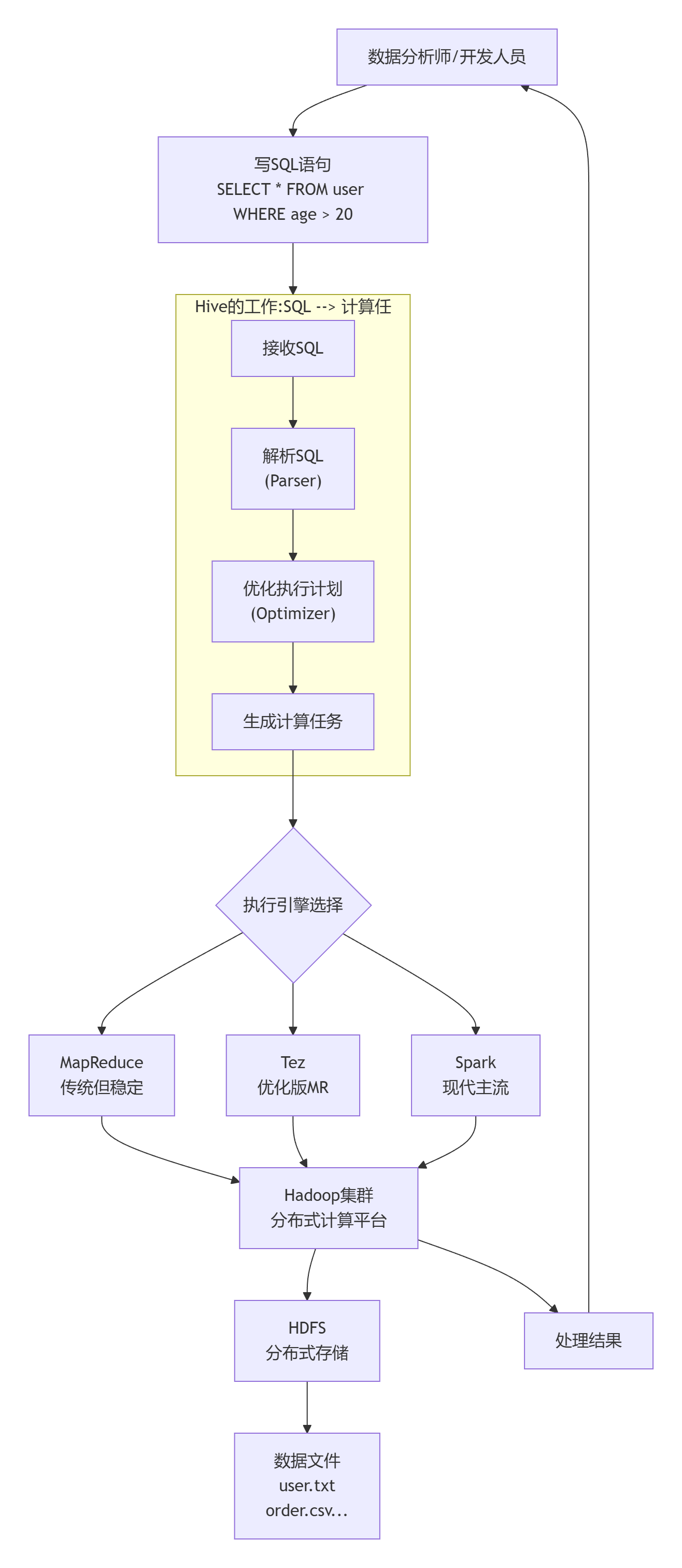
Hadoop和Hive的关系:一分钟彻底搞懂 │ 数据分析师/大数据开发 ││ 写SQL查询 │↓│ Hive ││ 把SQL翻译成分布式计算任务 ││ │ Metastore: 知道数据在哪、什么结构 │ ││ │ HiveQL: SQL方言 ... 国内服务器 2个月前310