计算机毕业设计Python+PySpark+DeepSeek大模型动漫推荐系统 动漫可视化 动漫爬虫 动漫大数据(代码+LW文档+PPT+讲解视频) 摘要:本文介绍了一个基于Python+PySpark+DeepSeek大模型的动漫推荐系统开发项目。系统整合多模态数据(文本、图像、音频)和用户行为数据,采用混合推荐算法(深度学习+协同过滤)实现个性... 国内服务器 6个月前760
【实战经验】解决ComfyUI加载报错:PytorchStreamReader failed reading zip archive: failed finding central directory 摘要 ComfyUI用户常遇到"PytorchStreamReader failed reading zip archive"错误,主要表现为模型加载失败。经分析... 国内服务器 6个月前760
Java 大视界 — Java 大数据在智能政务数字身份认证与数据安全共享中的应用 深入剖析 Java 大数据在智能政务身份认证与数据共享中的应用,融入丰富案例与代码,提供实用技术指引。 国内服务器 6个月前760
大数据新视界 — 大数据大厂之经典案例解析:广告公司 Impala 优化的成功之道(下)(10/30) 本文深入探讨广告公司 Impala 优化。阐述广告数据困境,分析 Impala 优化策略,包括存储(格式选择与分区策略对比)和查询(索引、语句改写)优化。通过广告巨头 Y 案例展现优化过程和效果。强调... 国内服务器 6个月前760
人工智能与机器学习:从理论到实践的技术全景 人工智能(AI)作为计算机科学的重要分支,旨在创造能够模拟人类智能行为的系统。而机器学习(ML)则是实现这一目标的核心方法,它使计算机能够从数据中"学习"而无需显式编程。从李宏毅教... 国内服务器 6个月前760
【仿RabbitMQ实现消息队列项目】交换机智能路由、队列流量隔离、绑定信息精准定向、消息可靠投递——四模块协同打造低耦合消息系统! 本篇将从对应的项目的交换机 队列 绑定信息 消息 这四个模块来介绍如何设计,以及如何实现(如根据标记位是否可持久化分为内存级别还是同时写入文件)。 国内服务器 6个月前760
Kafka – CPU使用率过高:热点分区排查与优化方案 整体CPU负载飙升:监控工具显示Kafka Broker所在的服务器CPU使用率长时间处于高位(例如超过80%或90%)。特定Broker负载异常:在多Broker集群中,某个或某几个Broker的C... 国内服务器 6个月前760
大数据深度学习|计算机毕设项目|计算机毕设答辩|PyQt基于深度学习的道路裂缝研究 1 绪论1.1研究背景与意义随着城市化进程的加速,道路作为关键的基础设施,其安全性和耐久性变得至关重要。然而,受到车辆超载、自然侵蚀等多种因素的影响,道路裂缝问题日益凸显,这不仅威胁到道路的结构安全... 国内服务器 6个月前760
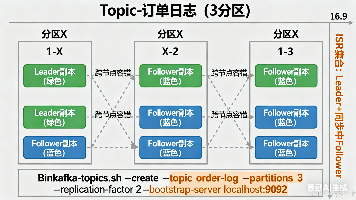
【分布式利器:Kafka】1、Kafka 入门:Broker、Topic、分区 3 张图讲透(附实操命令) 摘要:本文通过快递网点、分类筐和小格子的生动比喻,直观解析Kafka三大核心概念。Broker是存储转发消息的物理服务器节点,Topic是逻辑消息分类容器,分区则是实现并行处理的最小单元。文章提供可视... 国内服务器 6个月前760
【大数据基础】大数据处理架构Hadoop:02 Hadoop生态系统 本文讲解Hadoop生态系统,涵盖HDFS、HBase等众多组件。它们各司其职,协同运作,在数据存储、处理、分析、协同及管理等方面发挥优势,为大数据应用提供全面支撑。 国内服务器 6个月前760