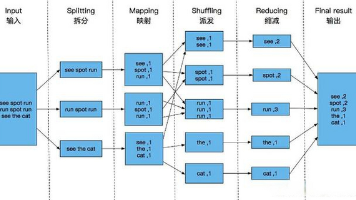
大数据领域Zookeeper的集群配置自动化工具推荐 在大数据生态中,Zookeeper作为分布式系统的"协调大脑",其集群配置的可靠性直接影响Hadoop、HBase、Kafka等核心组件的稳定性。然而手动配置Zookeeper集群... 国内服务器 3个月前380
大数据 Cassandra 与其他数据库的对比分析 在当今大数据时代,数据量呈爆炸式增长,不同类型的数据库应运而生以满足各种数据存储和处理的需求。本文的目的就是对比分析 Cassandra 数据库与其他常见数据库的优缺点,范围涵盖关系型数据库如 MyS... 国内服务器 3个月前380
Flutter 三方库 sparky 的鸿蒙化适配指南 – 实现极简 2D 游戏引擎功能、支持高效精灵图渲染与跨端游戏逻辑 在 Flutter for OpenHarmony 的娱乐化开发领域,我们有时需要构建一些轻量级的小游戏或交互动效,但又不想引入像 Flame 这样的大型游戏引擎。sparky是一个定位极其精简的 2... 国内服务器 3个月前380
Java实习模拟面试之京东Java后端开发一面(日常实习):聚焦Flink实时处理、Kafka高性能原理、HashMap底层与日志安全实践 大家好!最近我参加了一场高度仿真的京东2026届Java后端日常实习岗位模拟技术面试,全程约45分钟。面试官风格务实、节奏紧凑,问题覆盖项目深挖、大数据组件(Flink/Kafka)、Java核心(H... 国内服务器# Langchain 3个月前380
Spark SQL简介(1) 提起 Apache Spark,大家第一反应往往是“快”。确实,作为内存计算的标杆,Spark 的速度没得说。但在真实的业务场景里,Spark 生态中出场率最高、甚至可以说是“挑大梁”的角色,绝对是 ... 国内服务器 4个月前380
Hadoop MapReduce 螺蛳粉销量分析程序学习心得 本文分享了基于Hadoop MapReduce实现的螺蛳粉销量排序与月份分区程序的开发经验。通过拆解MapReduce"三步走"逻辑,详细说明了Mapper(数据拆... 国内服务器 3个月前380
HiveSQL 语法详解与常用 SQL 写法实战 用于创建、修改和删除数据库和表。HiveSQL 凭借其类 SQL 的语法、强大的批处理能力和与 Hadoop 生态的深度集成,成为大数据离线分析的主流工具之一。掌握其核心语法和常用写法,不仅能高效完成... 国内服务器 4个月前380
计算机毕业设计Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统 农产品销量预测 农产品推荐系统 智慧农业 本文介绍了一个基于Spark+Hadoop+Hive+LLM大模型+Django的农产品价格预测系统。系统通过整合多源数据(价格、天气、舆情等),采用五层分布式架构实现数据采集、存储、计算、预测与服务... 国内服务器 4个月前380
Java 大视界 — Java 大数据分布式计算在基因测序数据分析与精准医疗中的应用(400) 本文基于 5 家三甲医院实战,详解 Java 大数据分布式计算在基因测序数据分析中的应用。通过 “存储 - 预处理 - 分析 - 解读” 四阶架构,用 Hadoop 分片存储、Spark 并行处理、F... 国内服务器 4个月前380
大数据新视界 — Hive 事务管理的应用与限制(2 – 16 – 8) 本文深入探究 Hive 事务管理,详述应用场景、优势,剖析限制并提出应对策略,含代码示例,助力提升 Hive 事务处理能力。 国内服务器 4个月前380