Python大数据可视化:基于大数据技术的共享单车数据分析与辅助管理系统_flask+hadoop+spider 在搭建过程中,最开始的工作是从查阅相关资料开始的,通过在互联网的共享单车数据分析与辅助管理系统资料查询和阅读,对整个共享单车数据分析与辅助管理系统有了整体的概念了解,然后对本共享单车数据分析与辅助管理... 国内服务器 3个月前210
基于Python大数据旅游数据分析与推荐系统的爬虫 数据分析可视化系统 该系统基于Python技术栈构建,整合了网络爬虫、大数据分析、机器学习推荐算法及可视化技术,旨在为旅游行业提供数据驱动的决策支持与个性化服务。数据采集层采用Scrapy框架爬取主流旅游平台(如携程、T... 国内服务器 3个月前320
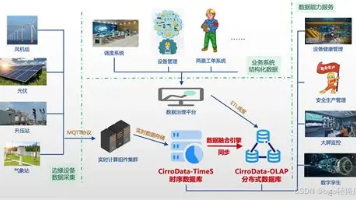
2026时序数据库选型全指南:大数据场景下的国产最优解,IoTDB实力领跑 随着工业物联网、智慧城市等领域时序数据爆发式增长,时序数据库成为大数据架构核心组件。本文提出时序数据库选型六大维度:高吞吐写入、高效存储压缩、快速查询、轻量化扩展、生态兼容及本土化服务。重点推荐国产开... 国内服务器 3个月前290
RabbitMQ和RocketMQ,哪个更好? 最近有球友问我:苏三哥,现在一般的项目中的消息中间件,是用RabbitMQ,还是RocketMQ,更好?这是一个非常常见的问题。今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。Rabbi... 国内服务器 3个月前280
HBase数据库:分布式列式存储的王者之路 摘要:HBase数据库的分布式列式存储解析 HBase作为Apache Hadoop生态中的分布式列式数据库,以其卓越的海量数据处理能力解决了传统关系型数据库的扩展瓶颈。本文深入剖析了HBase的核心... 国内服务器 3个月前760
Kafka Producer 与 Consumer 深度解析:消息生产与消费的完整旅程 角色定义主要职责Producer(生产者)向 Kafka 主题发布消息的应用程序创建消息、序列化、选择分区、发送到 BrokerConsumer(消费者)从 Kafka 主题订阅并处理消息的应用程序订... 国内服务器 3个月前300
学会大数据领域数据清洗,提高数据处理效率 完全重复:所有字段都相同(比如同一行数据被导入两次);逻辑重复:关键字段组合重复(比如同一用户、同一时间、同一商品的订单)。我们的场景中,逻辑重复是重点(完全重复很少见),需要用组合判断。数据清洗的本... 国内服务器 3个月前260
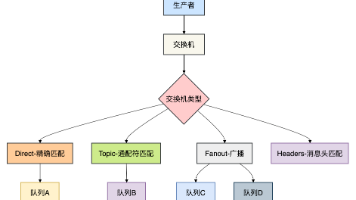
【Kafka基础篇】搞懂Kafka架构不用死记硬背:Topic与Partition映射逻辑一文讲透 Kafka作为分布式消息队列的核心组件,其架构围绕Producer、Broker、Consumer三大核心模块协作实现高吞吐、高可用。Producer负责消息发送,支持分区选择、批量发送和重试机制;B... 国内服务器 3个月前280
Java 大视界 — Java 大数据在智能教育在线考试系统中的考试结果分析与教学反馈优化中的应用(420) 本文聚焦智能教育在线考试系统 “分析浅、反馈慢、个性化弱” 痛点,结合 Java 大数据技术(Spark/Flink/Elasticsearch),拆解多维考试结果分析、实时个性化反馈两大核心场景,附... 国内服务器 3个月前390
ComfyUI与Zookeeper协调服务集成:分布式环境同步 本文探讨如何通过Apache Zookeeper实现ComfyUI在分布式环境中的服务发现、配置同步与任务队列管理,解决多节点协同中的状态一致性与容错问题,提升AI生成工作流的可靠性与可扩展性。 国内服务器 3个月前240