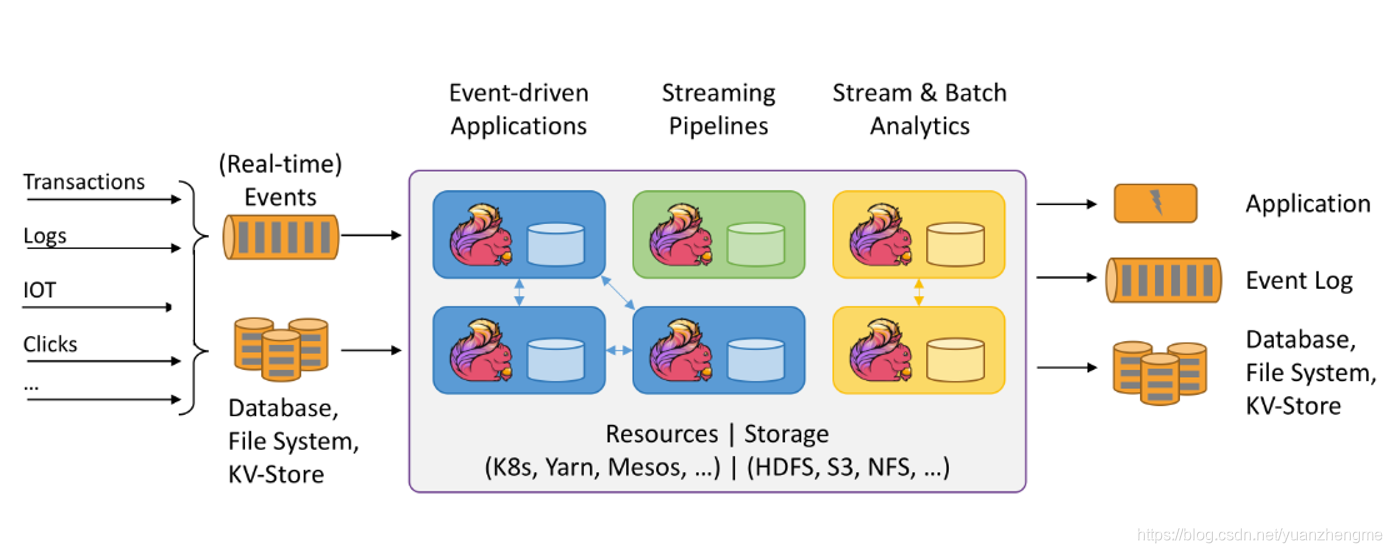
Flink【基础知识 01】简介+核心架构+分层API+集群架构+应用场景+特点优势(一篇即可大概了解Flink) 摘要:Apache Flink 是一个支持高吞吐、低延迟的实时分布式处理框架,能够对有界和无界数据流进行有状态计算。其核心架构分为API层、Runtime层和部署层,支持流批统一处理。Flink采用分... 国内服务器 6个月前850
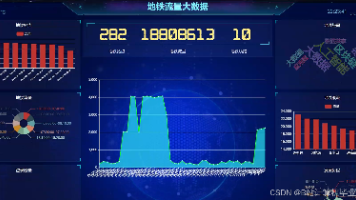
计算机毕业设计hadoop+spark+hive地铁预测可视化 智慧轨道交通系统 大数据毕业设计(源码+文档+PPT+讲解) 本项目基于Hadoop+Spark+Hive构建地铁客流量预测系统,采用四层架构实现数据采集、存储处理、分析预测和可视化展示。核心功能包括:通过Flume采集多源数据(日均500万条),使用Hive构... 国内服务器 6个月前840
libarchive: 一个几乎可以解压所有压缩文件的C语言库 libarchive 是跨平台开源 C 库(BSD 协议,可免费商用),原生支持解压 / 创建 tar、tar.gz、tar.bz2、tar.xz、zip、7z、rar(仅解压)等几乎所有主流压缩格式... 国内服务器 5个月前830
Java 大视界 — Java 大数据在智能家居环境监测与智能调节中的应用拓展(423) 本文探讨了Java大数据在智能家居环境监测与智能调节中的应用。当前智能家居存在设备数据异构化、决策滞后等痛点,导致用户体验不佳。作者通过实战项目经验,提出基于Java技术栈的解决方案:使用MQTT协议... 国内服务器 5个月前830
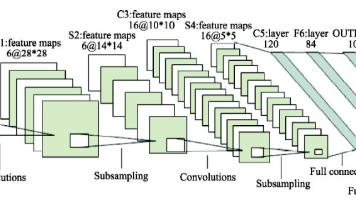
【AI 学习】揭开AI卷积神经网络的神秘面纱:从理论到实战 卷积神经网络(CNN)是处理图像等网格数据的深度学习模型,通过卷积层、池化层等结构自动提取特征。从LeNet-5到ResNet,CNN经历了多代演进,在图像分类、目标检测等领域表现卓越。卷积层通过滑动... 国内服务器 6个月前830
spark、mapreduce、flink核心区别及浅意理解 主流分布式数据处理框架对比:MapReduce、Spark和Flink分别代表批处理、内存计算和流批一体三个技术时代。MapReduce适合超大规模离线处理但延迟高;Spark在批处理和准实时场景表现... 国内服务器 6个月前830
【RabbitMQ】安装详解 && 什么是MQ && RabbitMQ介绍 本文介绍了在Ubuntu系统下安装、配置和使用RabbitMQ消息队列服务的详细步骤。主要内容包括: 安装Erlang语言环境(RabbitMQ的运行依赖) 安装RabbitMQ服务端及管理界面插件 ... 国内服务器 6个月前830